由于工作上的一些调整,目前开始接触容器化技术了。容器化技术相对于虚拟机的最大区别,在于其只是在操作系统上做了资源隔离和控制,而虚拟机则会基于原有的操作系统,模拟一整套硬件设备接口,运行一个新的操作系统及相关的 Lib 库。
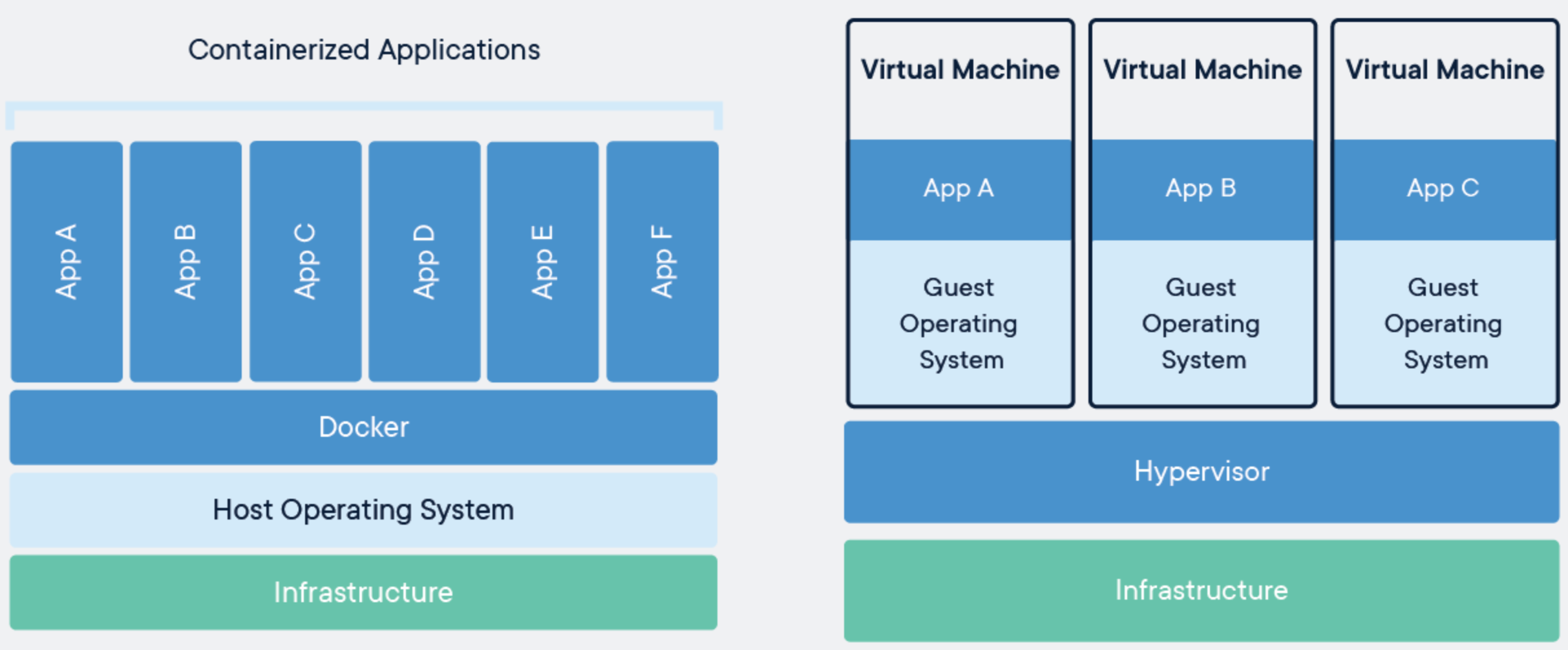
Copied From docker.com
如何实现容器化,显然需要从操作系统层面进行支撑。这其中涉及到的核心技术,就包括命名空间(namespace)和控制组(Control Group, cgroup),前者用来对资源进行隔离,后者用来对资源加以限制。
本文所有涉及的内核代码基于版本 3.10.1 ;所有命令执行结果基于 Ubuntu 18.04
Namespace
命名空间用来对资源进行隔离,每类资源都有一种命名空间,比如 ipc_namespace 用来对 IPC 资源进行隔离,pid_namespace 用来对可见的进程id进行隔离。
首先确定一下命名空间与任务之间的关系。用户与操作系统的任何交互,都是基于任务开始的,内核也是基于任务进行的调度。(关于“任务”与“进程、线程”之间的关系,详见Context of Execution。下文不区分"进程、线程",统一使用内核概念——任务)
每个任务都维护一个该任务所属的命名空间集合(其中包括该任务所属的 UTS 命名空间,IPC 命名空间等)。
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns;
struct net *net_ns;
};
struct task_struct {
// ... something omitted
struct nsproxy nsproxy;
}
如果想要查看现有的一些任务所属的命名空间,可以使用命令 ls -l /proc/[PID]/ns 。如果两个任务的某类命名空间 inode 编号一致,则说明两任务处于同一命名空间之下。
ls -l /proc/20/ns
total 0
lrwxrwxrwx 1 root root 0 Jun 15 08:38 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 root root 0 Jun 15 08:38 mnt -> 'mnt:[4026531840]'
lrwxrwxrwx 1 root root 0 Jun 15 08:38 net -> 'net:[4026531993]'
lrwxrwxrwx 1 root root 0 Jun 15 08:38 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Jun 15 08:38 uts -> 'uts:[4026531838]'
建立新的命名空间
最常见的创建新命名空间的方式是:在 clone 新任务的同时,携带诸如 CLONE_NEWNS, CLONE_NEWPID 之类的标志,系统调用 clone 将根据这些标志将新的任务 task 与新的命名空间进行关联。
static struct task_struct *copy_process(...)
{
// ... something omitted
retval = copy_namespaces(clone_flags, p)
// ... something omitted
}
int copy_namespaces(unsigned long flags, struct task_struct *tsk)
{
struct nsproxy *old_ns = tsk->nsproxy;
struct user_namespace *user_ns = task_cred_xxx(tsk, user_ns);
struct nsproxy *new_ns;
int err = 0;
if (!old_ns)
return 0;
// 为 old_ns 添加一个引用计数
get_nsproxy(old_ns);
// 如果不存在创建新的 CLONE_NEWxx 标志,意味着不需要创建新的命名空间
if (!(flags & (CLONE_NEWNS | CLONE_NEWUTS | CLONE_NEWIPC |
CLONE_NEWPID | CLONE_NEWNET)))
return 0;
// 只有 CAP_SYS_ADMIN 允许创建新的命名空间
if (!ns_capable(user_ns, CAP_SYS_ADMIN)) {
err = -EPERM;
goto out;
}
// CLONE_NEWIPC 与 CLONE_SYSVSEM 是互斥的标志位,需要保证不同时出现
if ((flags & CLONE_NEWIPC) && (flags & CLONE_SYSVSEM)) {
err = -EINVAL;
goto out;
}
// 创建新的命名空间
new_ns = create_new_namespaces(flags, tsk, user_ns, tsk->fs);
if (IS_ERR(new_ns)) {
err = PTR_ERR(new_ns);
goto out;
}
// 新的命名空间绑定到新的任务上
tsk->nsproxy = new_ns;
out:
put_nsproxy(old_ns);
return err;
}
static struct nsproxy *create_new_namespaces(unsigned long flags,
struct task_struct *tsk, struct user_namespace *user_ns,
struct fs_struct *new_fs)
{
struct nsproxy *new_nsp;
int err;
// 为新的 nsproxy 数据结构申请内存
new_nsp = create_nsproxy();
if (!new_nsp)
return ERR_PTR(-ENOMEM);
/*
* 对每类命名空间,逐一执行拷贝的动作。
* 当然,如果 flags 未配置 CLONE_NEWxx,该命名空间直接引用老的命名空间
*/
new_nsp->mnt_ns = copy_mnt_ns(flags, tsk->nsproxy->mnt_ns, user_ns, new_fs);
// something omitted ...
new_nsp->uts_ns = copy_utsname(flags, user_ns, tsk->nsproxy->uts_ns);
// something omitted ...
new_nsp->ipc_ns = copy_ipcs(flags, user_ns, tsk->nsproxy->ipc_ns);
// something omitted ...
new_nsp->pid_ns = copy_pid_ns(flags, user_ns, tsk->nsproxy->pid_ns);
// something omitted ...
new_nsp->net_ns = copy_net_ns(flags, user_ns, tsk->nsproxy->net_ns);
// something omitted ...
return new_nsp;
}
mnt_namespace 在对应的标志位为 CLONE_NEWNS,这是个历史遗留问题,早期认为只有文件系统需要命名空间,所以直接把 NS 赋予了 mnt_namespace 作为标志。
struct mnt_namespace *copy_mnt_ns(unsigned long flags, struct mnt_namespace *ns,
struct user_namespace *user_ns, struct fs_struct *new_fs)
{
struct mnt_namespace *new_ns;
BUG_ON(!ns);
// 为 ns 添加一个引用计数
get_mnt_ns(ns);
// 如果 CLONE_NEWNS 没有置位,直接返回老的 mnt 命名空间
if (!(flags & CLONE_NEWNS))
return ns;
// 按原来的 ns 拷贝一份新的 mnt_namespace
new_ns = dup_mnt_ns(ns, user_ns, new_fs);
// 释放对 ns 的引用
put_mnt_ns(ns);
return new_ns;
}
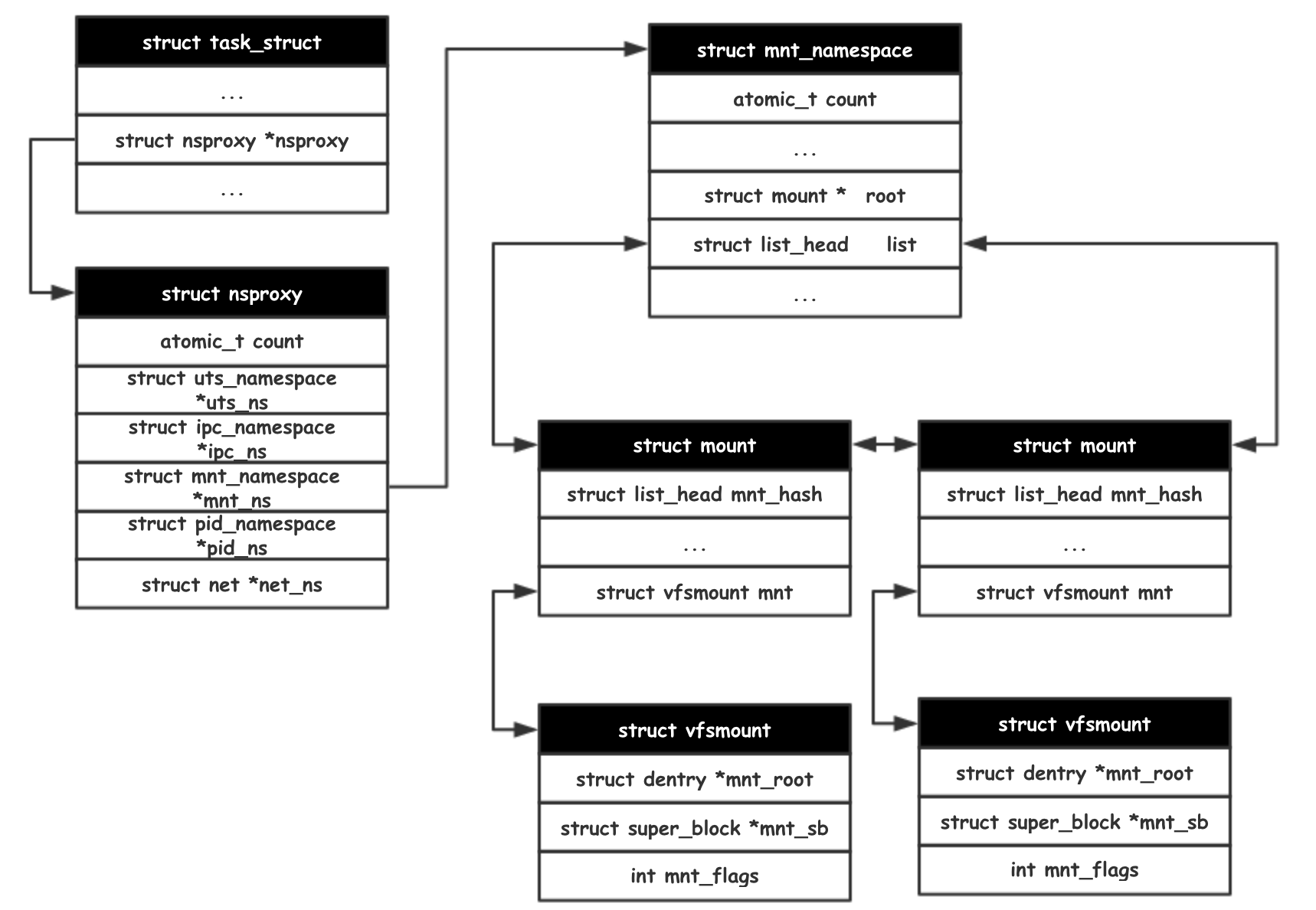
其它命名空间的操作类似,都是依据相关的 clone flag 决定是拷贝一份新的命名空间,或者是继续使用老的命名空间。而通过拷贝新的命名空间,相关的资源维护也就变得独立于原有的命名空间,从而达到资源隔离的目的。
完成命名空间的拷贝之后,之后的操作显得相当平凡,不管是用原来的命名空间,还是新的命名空间,总之都已经绑定到 struct task_struct->nsproxy 上,只需要普通的使用就可以了。
使用命名空间
以 PID 命名空间为例,现在需要为新的任务分配一个新的任务id,调用链开始于 clone -> do_fork -> copy_process -> alloc_pid。
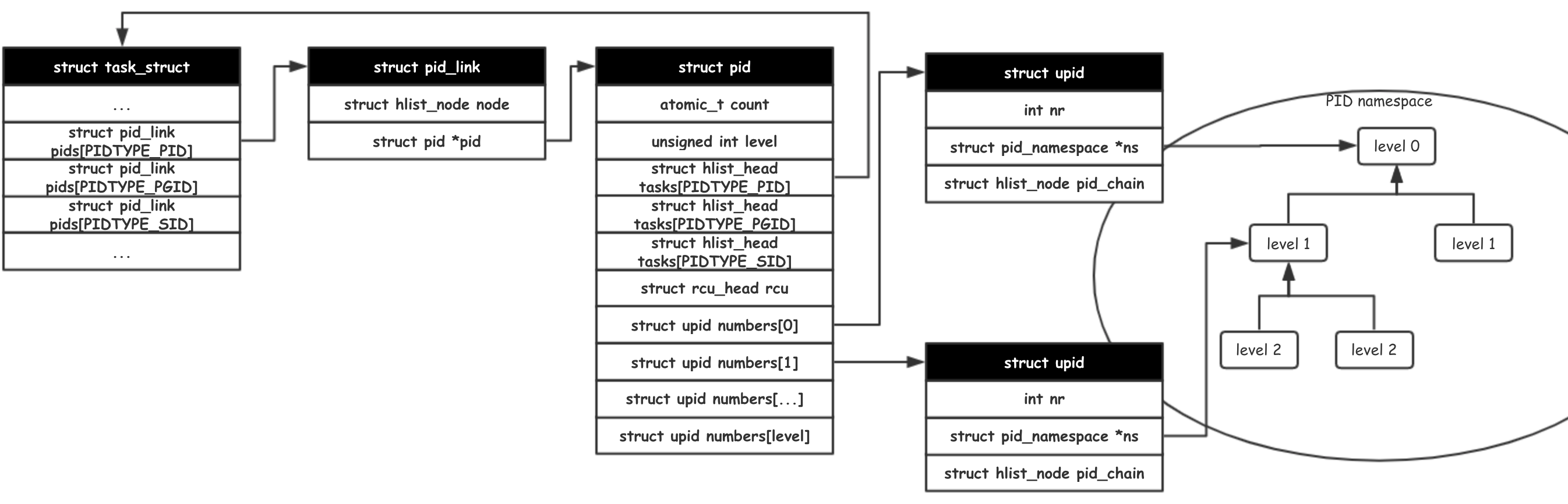
static struct task_struct *copy_process(...)
{
// ... something omitted
retval = copy_namespaces(clone_flags, p);
// ... something omitted
pid = alloc_pid(p->nsproxy->pid_ns);
// ... something omitted
}
struct pid *alloc_pid(struct pid_namespace *ns)
{
struct pid *pid;
enum pid_type type;
int i, nr;
struct pid_namespace *tmp;
struct upid *upid;
pid = kmem_cache_alloc(ns->pid_cachep, GFP_KERNEL);
if (!pid)
goto out;
tmp = ns;
pid->level = ns->level;
// PID 需要在每层PID命名空间获得一个唯一的 number (known as upid.nr)
for (i = ns->level; i >= 0; i--) {
/*
* 从 pidmap 中取出一个可用的 id
* 这里的 pidmap 是个位图,主要是为了提高效率而使用。
*/
nr = alloc_pidmap(tmp);
if (nr < 0)
goto out_free;
pid->numbers[i].nr = nr;
pid->numbers[i].ns = tmp;
tmp = tmp->parent;
}
if (unlikely(is_child_reaper(pid))) {
if (pid_ns_prepare_proc(ns))
goto out_free;
}
get_pid_ns(ns);
atomic_set(&pid->count, 1);
for (type = 0; type < PIDTYPE_MAX; ++type)
INIT_HLIST_HEAD(&pid->tasks[type]);
upid = pid->numbers + ns->level;
spin_lock_irq(&pidmap_lock);
if (!(ns->nr_hashed & PIDNS_HASH_ADDING))
goto out_unlock;
for ( ; upid >= pid->numbers; --upid) {
hlist_add_head_rcu(&upid->pid_chain,
&pid_hash[pid_hashfn(upid->nr, upid->ns)]);
upid->ns->nr_hashed++;
}
spin_unlock_irq(&pidmap_lock);
out:
return pid;
out_unlock:
spin_unlock_irq(&pidmap_lock);
out_free:
while (++i <= ns->level)
free_pidmap(pid->numbers + i);
kmem_cache_free(ns->pid_cachep, pid);
pid = NULL;
goto out;
}
需要注意的是,并不是所有的命名空间都建立起了父子节点的层级关联。此处只是以 PID 作为一个简单的示例。
示例
/* fns.c */
#define _GNU_SOURCE
#include <sys/wait.h>
#include <sched.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define errExit(msg) do { perror(msg); exit(EXIT_FAILURE); } while (0)
static int childFunc(void *arg)
{
execv("/bin/bash", NULL);
return 0;
}
#define STACK_SIZE (1024 * 1024)
int main(int argc, char **argv)
{
char *stack;
char *stackTop;
pid_t pid;
/* 为子任务申请栈内存 */
stack = malloc(STACK_SIZE);
if (stack == NULL)
errExit("malloc");
stackTop = stack + STACK_SIZE;
pid = clone(childFunc, stackTop, CLONE_NEWUTS | CLONE_NEWNS | CLONE_NEWPID | CLONE_NEWIPC | SIGCHLD, NULL);
if (pid == -1)
errExit("clone");
printf("clone() returned %ld\n", (long) pid);
sleep(1);
if (waitpid(pid, NULL, 0) == -1)
errExit("waitpid");
printf("child has terminated\n");
exit(EXIT_SUCCESS);
}
编译命令 gcc -o fns fns.c -w
执行指令 ./fns 将进入一个新的 bash,此时的 UTS、VFS、PID、IPC 命名空间都是全新的。所有基于这些命名空间而存在的概念将不会对 root 命名空间产生影响。
Control Group
对命名空间有了初步的概念之后,再看看 Control Group —— 用来限制任务能够使用的资源上限,当然,还可以调整进程优先级、进行资源统计、实现进程控制等。
cgroup 主要存在四大概念:
task,任务调度的基本单位,用户认知的进程/线程(详见 执行的上下文)
subsystem,子系统,Control Group 可以进行资源控制,每类可进行控制的资源作为一种子系统而存在。
cgroup,控制组,在划分后在各个子系统下,分别都有控制组来对现有的任务(task)进行划分,每个任务在单个子系统中只能从属于一个控制组,每个任务可以从属于多个不同的子系统。
hierarchy,层级树,每个子系统下,会有多个不同的控制组,它们共同维护起来树形的结构。在没有特别配置的情况下,每个子控制组将继承父控制组的限制。
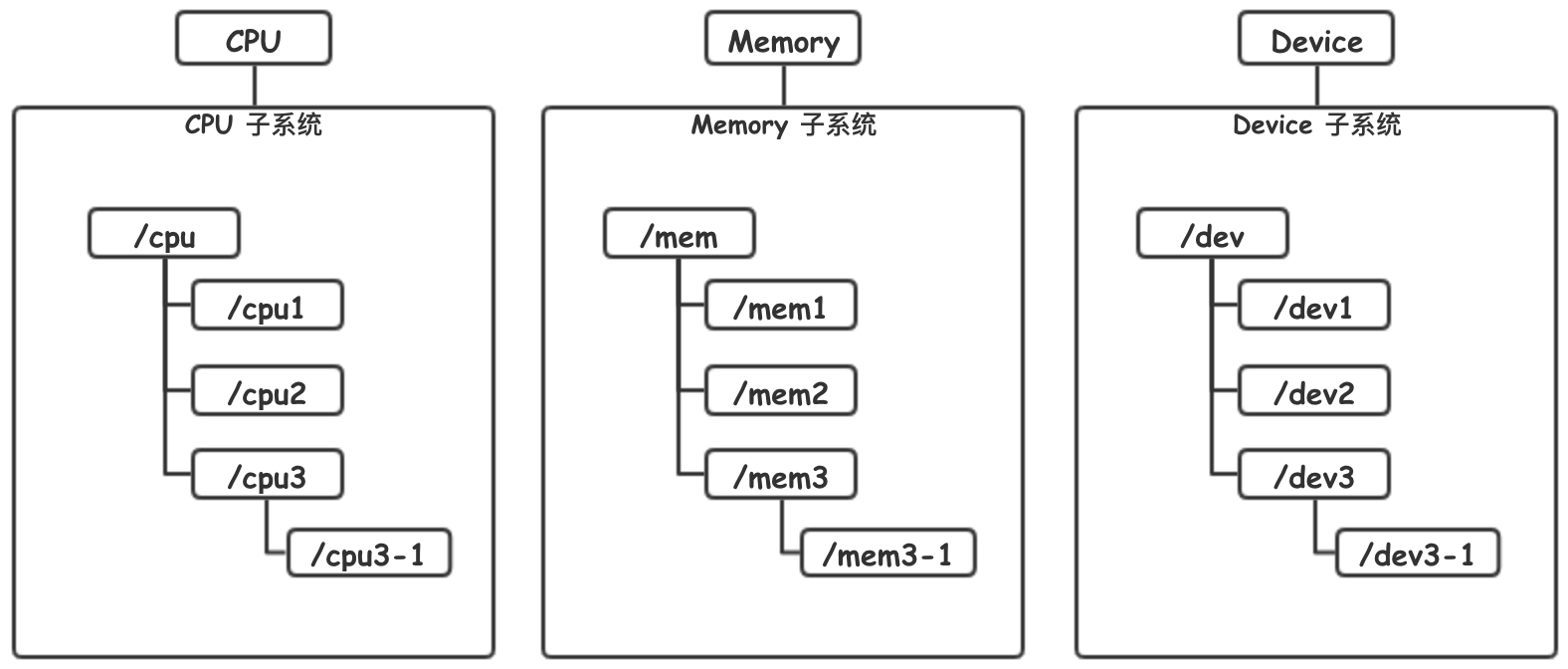
Cgroup 组织结构
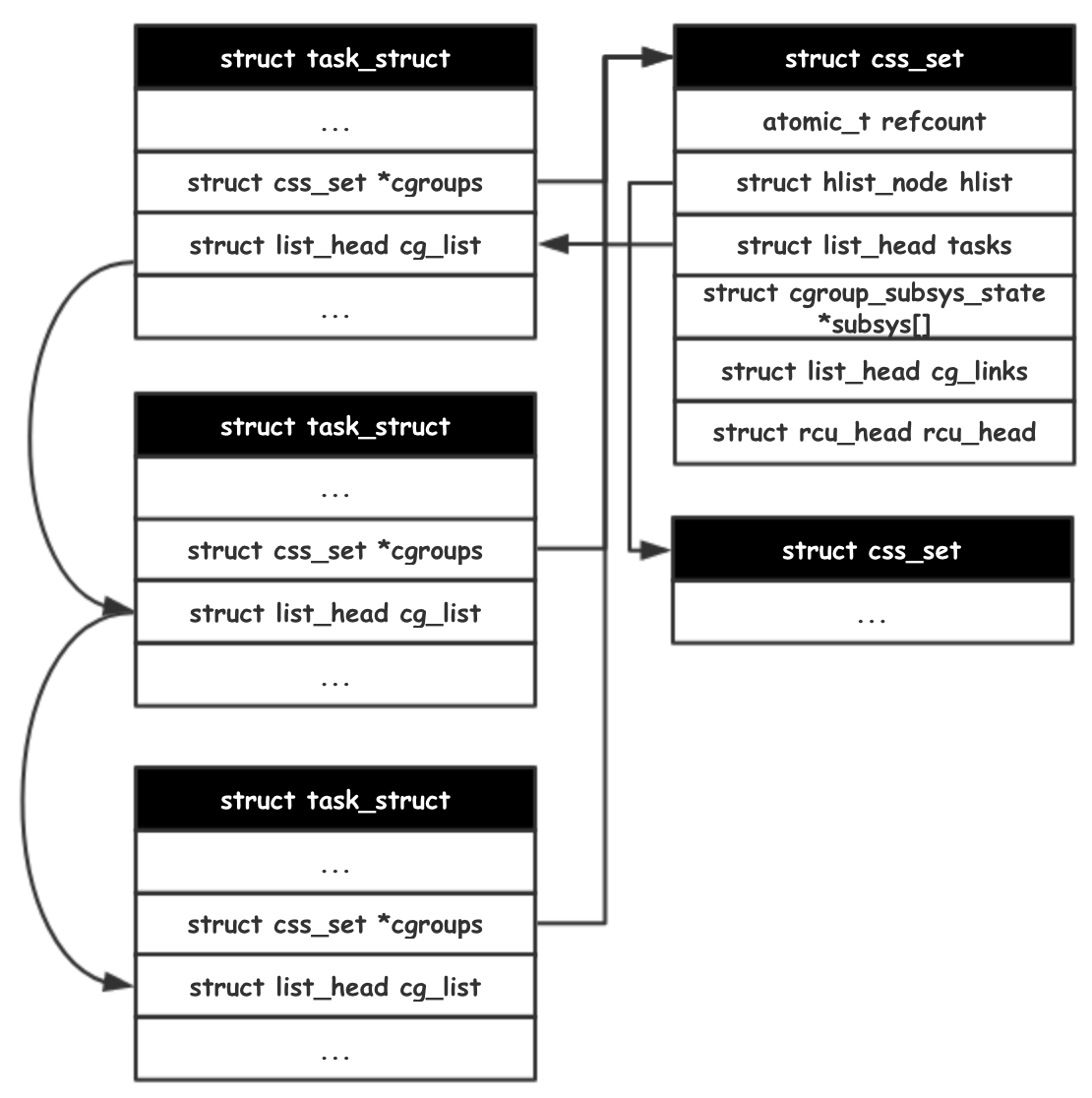
一个任务从属于一个控制组集合中(例如属于cpu子系统控制组-1,mem子系统控制组-3…)。将不同子系统控制组整合起来的数据结构就是 css_set(cgroup subsys state set)。一个控制组集合可以维护多个任务(通过列表的形式链接)。
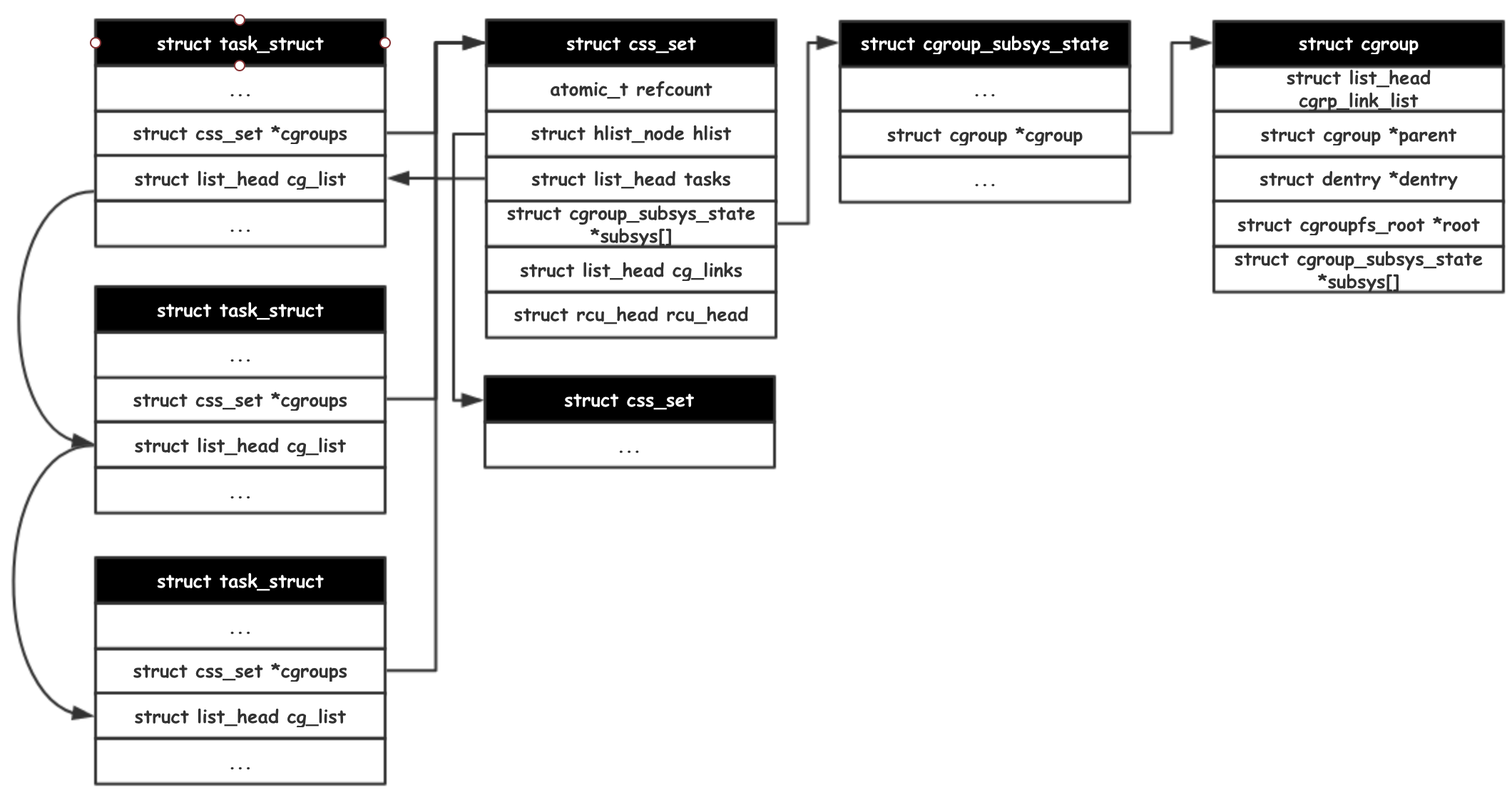
css_set 控制组集合中维护了一个 css 列表,每个 cgroup_subsys_state 执行一个 cgroup 结构(包含某一子系统控制组的所有信息)。通过这样的方式,任务就和一系列的子系统控制组联系起来了。
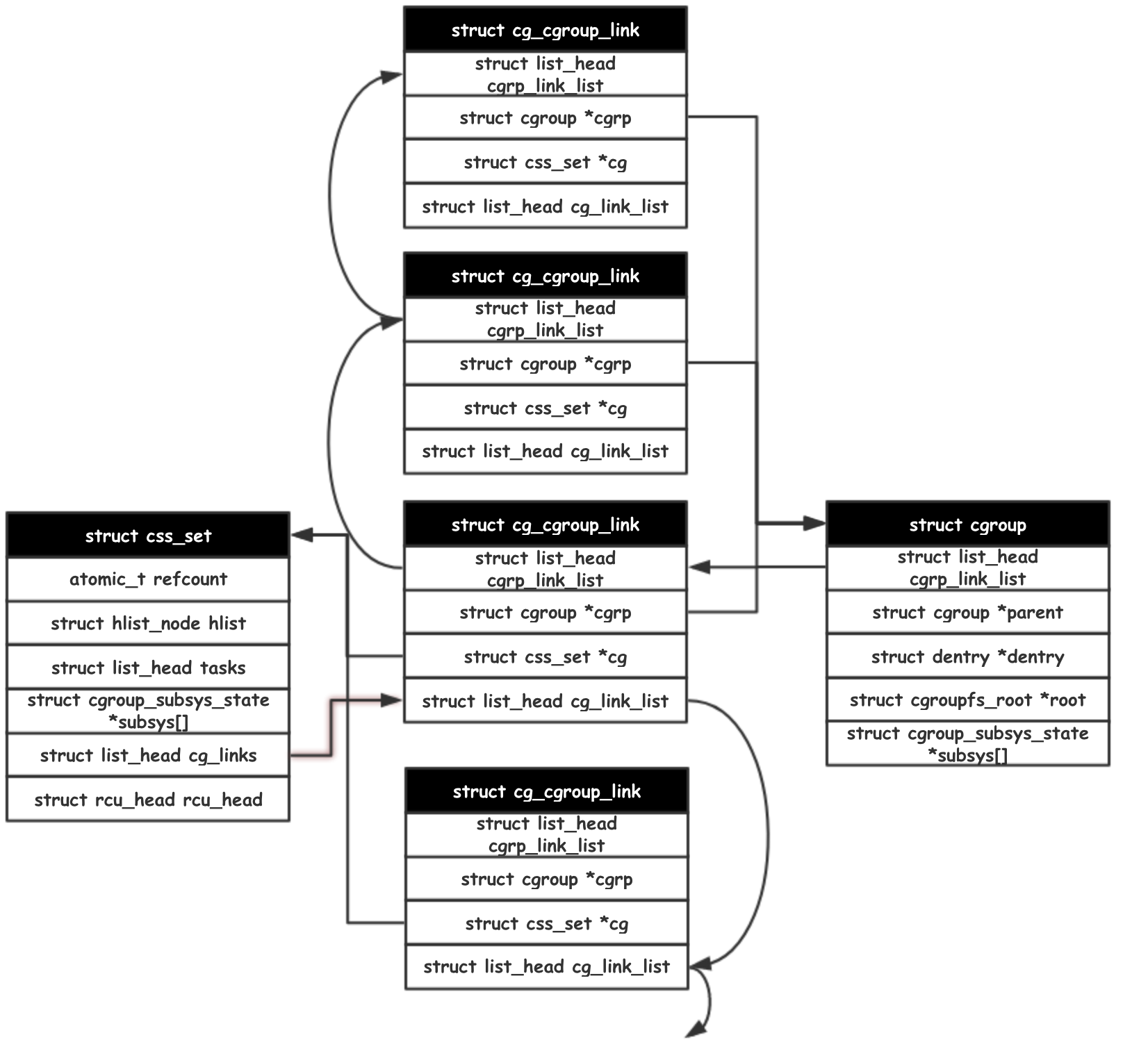
反向的,通过 cgroup 结构查找所有处于其控制下的任务。这里的 cgroup 与 css_set 是一个多对多的关系。一个 css_set 整合了多个 cgroup ,一个 cgroup 可以被多个 css_set 利用。cg_cgroup_link 就是一个处于中间的关联结构。(多对多的关系可以参考数据库建表,两个实体表 A, B 间需要通过第三张表 C 来描述 (A-id, B-id) 的关系)。
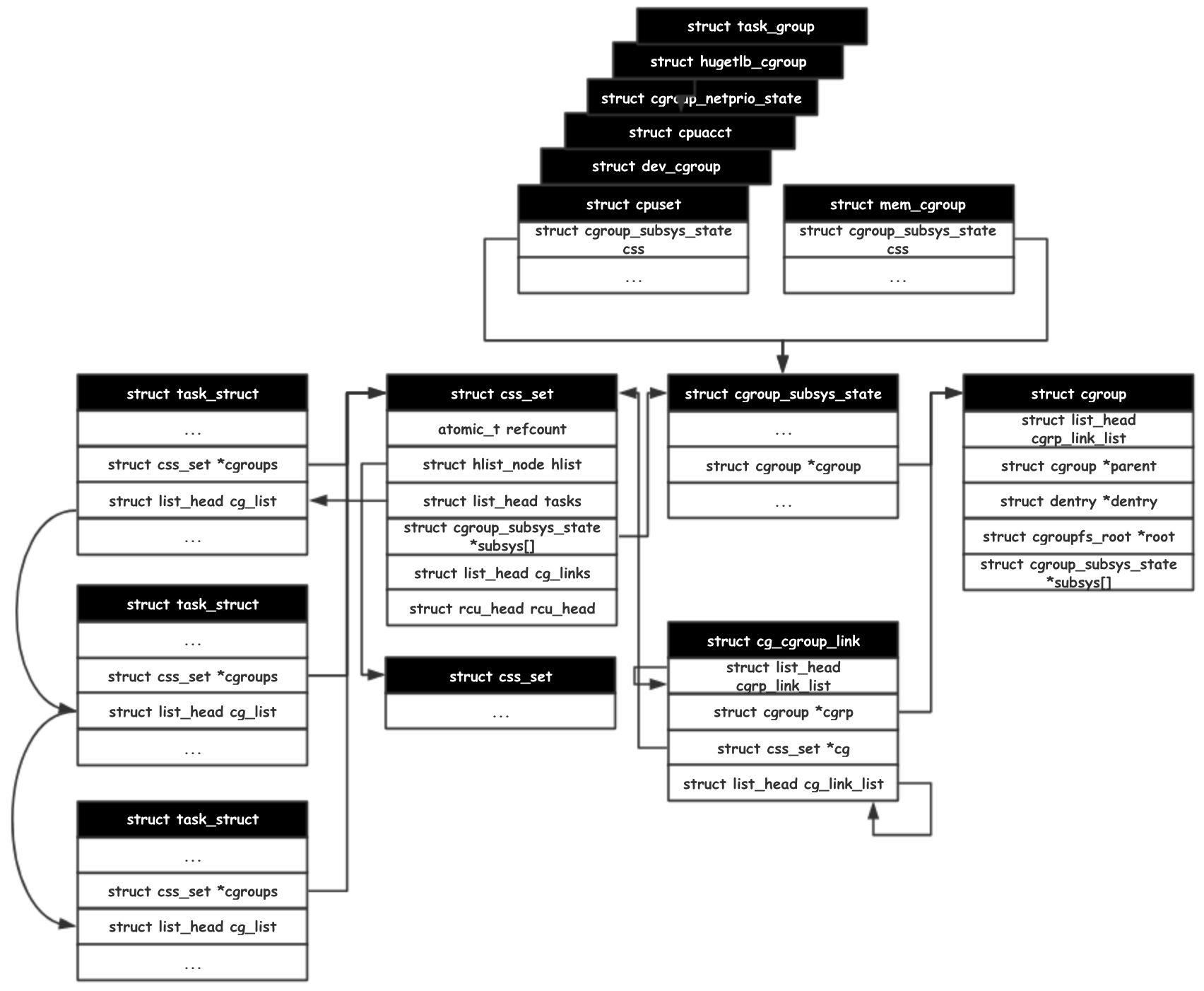
最后来看看 cgroup_subsys_state 结构,各个子系统结构的第一个参数都是 cgroup_subsys_state_css,通过内核的 container_of 函数,subsys[] 的每个元素都可以分别被认知为 cpuset , mem_cgroup 等。
这里还能看到一个现象,css_set 和 cgroup 都维护了 cgroup_subsys_state 的数组,这是为了加速访问而实现的。cgroup 作为调整参数的控制结构,通过实现 VFS 的接口对用户暴露读写等操作。而作为 Cgroup 的被控制对象的 task 也需要频繁地对其所受的资源限制进行检查。由于 task 没有与 cgroup 作直接关联,是一种多对多的关系,因此额外维护了一份 subsys[] ,来加速频繁的读操作。
Cgroup 实现资源控制的方式
Cgroup 归根结底是需要实现对任务的资源控制。
首先是新任务如何与 Cgroup 挂钩。
- 在系统启动阶段,
init/main.c中的代码初始化了 root cgroup ,并初始化第一个css_set挂载到创始任务上 - 此后,所有任务的产生和终结,将调用
cgroup_fork和cgroup_exit实现任务与css_set的互操作; - 在任务运行过程中,将任务从子系统的一个 cgroup 移动到另一个 cgroup,将使用
attach和detach进行操作。
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
// something omitted ...
cgroup_fork(p);
// something omitted ...
}
void cgroup_fork(struct task_struct *child)
{
task_lock(current);
// 直接引用当前任务(即父任务)的 cgroups 指针
// 这里的 cgroups 变量类型是 *css_set
child->cgroups = current->cgroups;
// 添加一个引用计数
get_css_set(child->cgroups);
task_unlock(current);
INIT_LIST_HEAD(&child->cg_list);
}
演示:限制 CPU 密集型任务的 CPU 资源使用量
演示程序
/* calc.c */
int main(int argc, char **argv)
{
for (unsigned long long i=0;1;i++);
}
编译后后台执行
$ # 编译
$ cc calc.c -o calc
$ # 后台执行
$ ./calc &
[1] 25828
$ # 观察 CPU 使用量
$ top
任务 calc 的 CPU 使用率基本上达到了 100% 左右。现在要将它限制到 50% 。
$ # 找到 cgroup 虚拟文件系统的挂载路径
$ mount | grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
cgroup on /sys/fs/cgroup/unified type cgroup2 (rw,nosuid,nodev,noexec,relatime)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
$ # 在 /sys/fs/cgroup/cpu,cpuacct/ 目录挂载的就是 cgroup cpu 子系统和 cpuacct 子系统
$ cd /sys/fs/cgroup/cpu,cpuacct/
$ # 创建一个新的 cgroup ,继承父 cgroup 的所有参数,但可以被修改。
$ # Cgroup 实现了虚拟文件系统的接口,可以像操作文件一样修改内核 Cgroup 的各个参数
$ mkdir ff
$ # 将 calc 任务加入的 ff cgroup 的管理下
$ echo "25828" > tasks
这样就把 calc 任务从一个 cgroup 转移到另一个 cgroup 的控制之下。不过,到目前为止,calc 任务仍然保持 CPU 100% 占用。毕竟这个 cgroup 的配置继承自父 cgroup ,都没有做任何限制。如何做限制呢?
cpu.cfs_period_us 和 cpu.cfs_quota_us 分别被用来描述完全公平调度器每微秒的周期数和每微秒使用的周期数
$ cat cpu.cfs_period_us
100000
$ cat cpu.cfs_quota_us
-1
目前使用中的 cpu.cfs_quota_us 是 -1,代码没有逻辑上限。为了将 calc 任务的 CPU 使用率调整到 50% ,修改 cpu.cfs_quota_us ,使其恰好为 cpu.cfs_period_us 的一半就可以了。
$ echo "50000" > cpu.cfs_period_us
OK,再检查 calc 任务,结果就基本稳定在 50% 的使用率。而 CPU 没有其它的高使用率负载。
小结
通过命名空间和控制组的配合,就基本达成了容器化的初级要求——资源隔离、资源限额。当然,关于网络相关的仍然存在疑问。
在控制组的使用中,突然回忆起以前的一个问题——如何编程实现一个任务的 CPU 使用率恰好是 X%?虽然通过编程合理计算指令执行时间也能实现,但用 Cgroup 来似乎更为简单。不过,这两者的控制层面已经有了很大的不同。
__ __
/ _| __ _ _ __ __ _ / _| ___ _ __ __ _
| |_ / _` | '_ \ / _` | |_ / _ \ '_ \ / _` |
| _| (_| | | | | (_| | _| __/ | | | (_| |
|_| \__,_|_| |_|\__, |_| \___|_| |_|\__, |
|___/ |___/