前一篇已经对 Linux 内核网络相关的内容进行了基础性的介绍。数据从到达网卡,到最终被用户进程获取,最少经过了三个进程/硬中断的配合:网络中断负责将网络接收到的数据读取到内存并添加到 softnet_data 队列,并设置软中断通知内核进程 ksoftirqd;内核进程 ksoftirqd 被调度并处于运行状态,处理位于 softnet_data 中的 struct sock 对象,将其逐级从网络接口层逐级提升到网络层、传输层…最终添加到接收队列 sk_receive_queue 中;用户进程通过 read、recv、recvfrom 等命令检查并获取 sk_receive_queue 中的数据。
整个流程从概述上可以很轻松地配合进行网络数据交互,但如果要监控多个网络套接字呢?处理流程将变得复杂。我们无法预知哪个套接字能优先接收到数据。因此,最直接的办法就是轮询,在用户程序硬编码,通过设置超时时间的方式尝试获取数据。当然,这个效率就相当低下了。每次试探都需要触发系统调用(要知道这代价可是相当大的),另外超时时间的设置也是一个硬性的阻塞式消耗。
那么,有没有解决方案呢?当然有。通过用户程序硬编码式的轮询显然是陷入性能瓶颈的根源。因此内核主动提供了轮询式的系统调用(select, poll, epoll)。通过将轮询逻辑下沉到内核态,系统调用就只会有一次,而且超时时间的设置也显得统一。本篇就要就 select 和 epoll 两类系统调用的实现进行探究。
SELECT
select 是一种比较古老的系统调用方式,存在着许多的调用限制。当然,相对的也就比较容易理解。
select 系统调用最初的逻辑就是对超时时间的相关操作,完成从用户数据段到内核数据段的数据拷贝工作,而使用 copy_from_user 的目的,虽然看似比较晦涩,不如大家在用户程序中普通调用的memcpy,但究其原因,是为了处理MMU相关的问题。将内核复制的数据timeval做一定的取整操作(因为硬件中断的精度可能达不到timeval所描述的粒度,故根据HZ做取整,恰好为时钟中断周期的整数倍)。调用 core_sys_select 进行真正的轮询操作(当然,好像也算不上真正的逻辑,还有一层核心的调用呢)。结束后的操作当然是准备更新timeval。因为进行轮询的结果有两种,一种是因为超时而结束 core_sys_select 函数调用;另一种是得到了一个或多个准备就绪的数据,才结束调用并返回。显然,因为第二种结果而更新timeval有着一定的实际意义——到底等待了多久。不过这里需要注意的是,不是所有的Linux系统都支持对timeval做更新。
asmlinkage long sys_select(int n, fd_set __user *inp, fd_set __user *outp,
fd_set __user *exp, struct timeval __user *tvp)
{
s64 timeout = -1;
struct timeval tv;
int ret;
/* 如果设置了超时时间 */
if (tvp) {
if (copy_from_user(&tv, tvp, sizeof(tv)))
return -EFAULT;
/* 计时器不能设置为负数 */
if (tv.tv_sec < 0 || tv.tv_usec < 0)
return -EINVAL;
/* Cast to u64 to make GCC stop complaining */
/* 对 timeout 做一定的处理,根据时钟周期对 usec 进行取整 */
if ((u64)tv.tv_sec >= (u64)MAX_INT64_SECONDS)
timeout = -1; /* 无限等待 */
else {
timeout = DIV_ROUND_UP(tv.tv_usec, USEC_PER_SEC/HZ);
timeout += tv.tv_sec * HZ;
}
}
/* 核心的 select 实现逻辑 */
ret = core_sys_select(n, inp, outp, exp, &timeout);
/* 如果设置了超时时间 */
if (tvp) {
struct timeval rtv;
if (current->personality & STICKY_TIMEOUTS)
goto sticky;
rtv.tv_usec = jiffies_to_usecs(do_div((*(u64*)&timeout), HZ));
rtv.tv_sec = timeout;
if (timeval_compare(&rtv, &tv) >= 0)
rtv = tv;
/* 内核数据->用户数据的拷贝,更新距离超时剩余的时间间隔 */
if (copy_to_user(tvp, &rtv, sizeof(rtv))) {
sticky:
/*
* 如果应用程序把timeval放在只读内存中,内核就无需特别的更新它
* If an application puts its timeval in read-only
* memory, we don't want the Linux-specific update to
* the timeval to cause a fault after the select has
* completed successfully. However, because we're not
* updating the timeval, we can't restart the system
* call.
*/
if (ret == -ERESTARTNOHAND)
ret = -EINTR;
}
}
return ret;
}
core_sys_select 也没有太多核心操作,完全是在为三个位图——输入、输出、错误从用户数据段到内核数据段的拷贝工作,以及在结束 do_select 调用后的反向拷贝操作。不过,无论是 sys_select 还是 core_sys_select 都将各自需要完成的工作分割得非常清晰,一个完成timeval的处理工作,另一个完成位图的处理。
/*
* 内核数据-位图的准备,调用do_select完成核心的逻辑
*/
static int core_sys_select(int n, fd_set __user *inp, fd_set __user *outp,
fd_set __user *exp, s64 *timeout)
{
fd_set_bits fds;
void *bits;
int ret, max_fds;
unsigned int size;
struct fdtable *fdt;
/*
* 在栈中定义较小的数组,减少堆内存的占用,同时可以更快;
* SELECT_STACK_ALLOC = 256
*/
long stack_fds[SELECT_STACK_ALLOC/sizeof(long)];
ret = -EINVAL;
if (n < 0)
goto out_nofds;
/* max_fds can increase, so grab it once to avoid race */
/* max_fds 可能同时在增加,所以提前获取一份固定的拷贝避免竞争 */
rcu_read_lock();
/* 获取当前任务的文件描述符表 */
fdt = files_fdtable(current->files);
max_fds = fdt->max_fds;
rcu_read_unlock();
if (n > max_fds)
n = max_fds;
/*
* We need 6 bitmaps (in/out/ex for both incoming and outgoing),
* since we used fdset we need to allocate memory in units of
* long-words.
*/
size = FDS_BYTES(n);
bits = stack_fds;
if (size > sizeof(stack_fds) / 6) {
/* Not enough space in on-stack array; must use kmalloc */
/* 栈数组大小不足;使用 kmalloc 获取新的空间 */
ret = -ENOMEM;
bits = kmalloc(6 * size, GFP_KERNEL);
if (!bits)
goto out_nofds;
}
fds.in = bits;
fds.out = bits + size;
fds.ex = bits + 2*size;
fds.res_in = bits + 3*size;
fds.res_out = bits + 4*size;
fds.res_ex = bits + 5*size;
/* 用户数据段的数据 inp、outp、exp 往内核数据段 fds.xxx 拷贝 */
if ((ret = get_fd_set(n, inp, fds.in)) ||
(ret = get_fd_set(n, outp, fds.out)) ||
(ret = get_fd_set(n, exp, fds.ex)))
goto out;
/* fds.res_xxx 作为 do_select 的执行结果,预置为0,表示每一位相应的fd都未准备就绪 */
zero_fd_set(n, fds.res_in);
zero_fd_set(n, fds.res_out);
zero_fd_set(n, fds.res_ex);
/* 交由 do_select 完成真正核心的操作 */
ret = do_select(n, &fds, timeout);
if (ret < 0)
goto out;
if (!ret) {
ret = -ERESTARTNOHAND;
if (signal_pending(current))
goto out;
ret = 0;
}
/* 将结果集拷贝回用户数据段的 inp、outp、exp 中 */
if (set_fd_set(n, inp, fds.res_in) ||
set_fd_set(n, outp, fds.res_out) ||
set_fd_set(n, exp, fds.res_ex))
ret = -EFAULT;
out:
if (bits != stack_fds)
kfree(bits);
out_nofds:
return ret;
}
终于是核心的逻辑了,逐一地将当前任务挂到相应文件的等待队列上,并等待调用 poll 函数被唤醒
int do_select(int n, fd_set_bits *fds, s64 *timeout)
{
struct poll_wqueues table;
poll_table *wait;
int retval, i;
rcu_read_lock();
/* 确认fds.xxx所需轮询的fd全部全部处于打开状态,同时返回最大的fd */
retval = max_select_fd(n, fds);
rcu_read_unlock();
if (retval < 0)
return retval;
n = retval;
/* 把当前任务放入自己的等待队列中 */
poll_initwait(&table);
wait = &table.pt;
/* 如果超时时间为0,即无需等待 */
if (!*timeout)
wait = NULL;
retval = 0;
/* 无限循环 */
for (;;) {
unsigned long *rinp, *routp, *rexp, *inp, *outp, *exp;
long __timeout;
set_current_state(TASK_INTERRUPTIBLE);
inp = fds->in; outp = fds->out; exp = fds->ex;
rinp = fds->res_in; routp = fds->res_out; rexp = fds->res_ex;
for (i = 0; i < n; ++rinp, ++routp, ++rexp) {
unsigned long in, out, ex, all_bits, bit = 1, mask, j;
unsigned long res_in = 0, res_out = 0, res_ex = 0;
const struct file_operations *f_op = NULL;
struct file *file = NULL;
in = *inp++; out = *outp++; ex = *exp++;
all_bits = in | out | ex;
if (all_bits == 0) {
i += __NFDBITS;
continue;
}
/* 对 unsigned long 的每一位进行确认 */
for (j = 0; j < __NFDBITS; ++j, ++i, bit <<= 1) {
int fput_needed;
/* 超过需检测的最大的文件描述符 */
if (i >= n)
break;
/* 该 fd 无需检测,直接下一个 */
if (!(bit & all_bits))
continue;
/* 获取相应的文件实例 */
file = fget_light(i, &fput_needed);
if (file) {
f_op = file->f_op;
mask = DEFAULT_POLLMASK;
/* 对于套接字,调用的是sock_poll,在poll成功时将唤醒wait队列的任务(即把当前任务唤醒)*/
if (f_op && f_op->poll)
mask = (*f_op->poll)(file, retval ? NULL : wait);
fput_light(file, fput_needed);
if ((mask & POLLIN_SET) && (in & bit)) {
res_in |= bit;
retval++;
}
if ((mask & POLLOUT_SET) && (out & bit)) {
res_out |= bit;
retval++;
}
if ((mask & POLLEX_SET) && (ex & bit)) {
res_ex |= bit;
retval++;
}
}
/* 主动让出CPU片,等待重新调度(提前设置了最高优先级PREEMPT_ACTIVE)*/
cond_resched();
}
if (res_in)
*rinp = res_in;
if (res_out)
*routp = res_out;
if (res_ex)
*rexp = res_ex;
}
wait = NULL;
if (retval || !*timeout || signal_pending(current))
break;
if(table.error) {
retval = table.error;
break;
}
if (*timeout < 0) {
/* Wait indefinitely */
__timeout = MAX_SCHEDULE_TIMEOUT;
} else if (unlikely(*timeout >= (s64)MAX_SCHEDULE_TIMEOUT - 1)) {
/* Wait for longer than MAX_SCHEDULE_TIMEOUT. Do it in a loop */
__timeout = MAX_SCHEDULE_TIMEOUT - 1;
*timeout -= __timeout;
} else {
__timeout = *timeout;
*timeout = 0;
}
/* 进入延时唤醒状态,待定预定的超时时间 */
__timeout = schedule_timeout(__timeout);
if (*timeout >= 0)
*timeout += __timeout;
}
__set_current_state(TASK_RUNNING);
poll_freewait(&table);
return retval;
}
总结来看,select 完全能够支持IO多路复用。至少比用户程序自行实现轮询优秀得多。但是,也存在着一些明显的缺陷:
- 支持的文件描述符存在上限,默认是1024。
- 每次陷入内核态
select函数之后,都需要按位遍历所有的文件描述符(无论该fd是否存在),max(fd)越大,开销越大。 - 每次调用
select都需要将fd集合从用户态复制到内核态,max(fd)越大,开销越大。
EPOLL
简单地描述过 select 系统调用之后,我们着重来聊一聊 epoll 的实现。毕竟 select 和 poll 的复杂度是 $O(N)$,而 epoll 只是 $O(\log{N})$ (当然,这里对时间复杂度的比较维度不同,稍候细讲)。epoll 区别于传统I/O复用模型的最大特色在于:它将创建并维护一个 eventpoll 实例,并通过注册请 epoll 对新的文件描述符进行监听,这意味着数据从用户数据区到内核数据区的拷贝只有一次;相对的,传统方式在每次轮询时,都需要全量地将数据从用户数据区拷贝到内核数据区。
epoll_create
epoll_create 负责创建一个新的 eventpoll 实例。这里的size并没有实际意义(由于历史原因而存在),传入的参数将被忽略。看源码总是件有意思的事,这个size被描述成了检查精神健全的标志…
asmlinkage long sys_epoll_create(int size)
{
int error, fd = -1;
struct eventpoll *ep;
struct inode *inode;
struct file *file;
DNPRINTK(3, (KERN_INFO "[%p] eventpoll: sys_epoll_create(%d)\n",
current, size));
/*
* 精神健全检测(size);同时建立内部数据结构 struct eventpoll
*/
error = -EINVAL;
if (size <= 0 || (error = ep_alloc(&ep)) != 0)
goto error_return;
/*
* 创建一个新的文件描述符,文件数据结构和i节点
*/
error = anon_inode_getfd(&fd, &inode, &file, "[eventpoll]",
&eventpoll_fops, ep);
if (error)
goto error_free;
DNPRINTK(3, (KERN_INFO "[%p] eventpoll: sys_epoll_create(%d) = %d\n",
current, size, fd));
return fd;
error_free:
ep_free(ep);
error_return:
DNPRINTK(3, (KERN_INFO "[%p] eventpoll: sys_epoll_create(%d) = %d\n",
current, size, error));
return error;
}
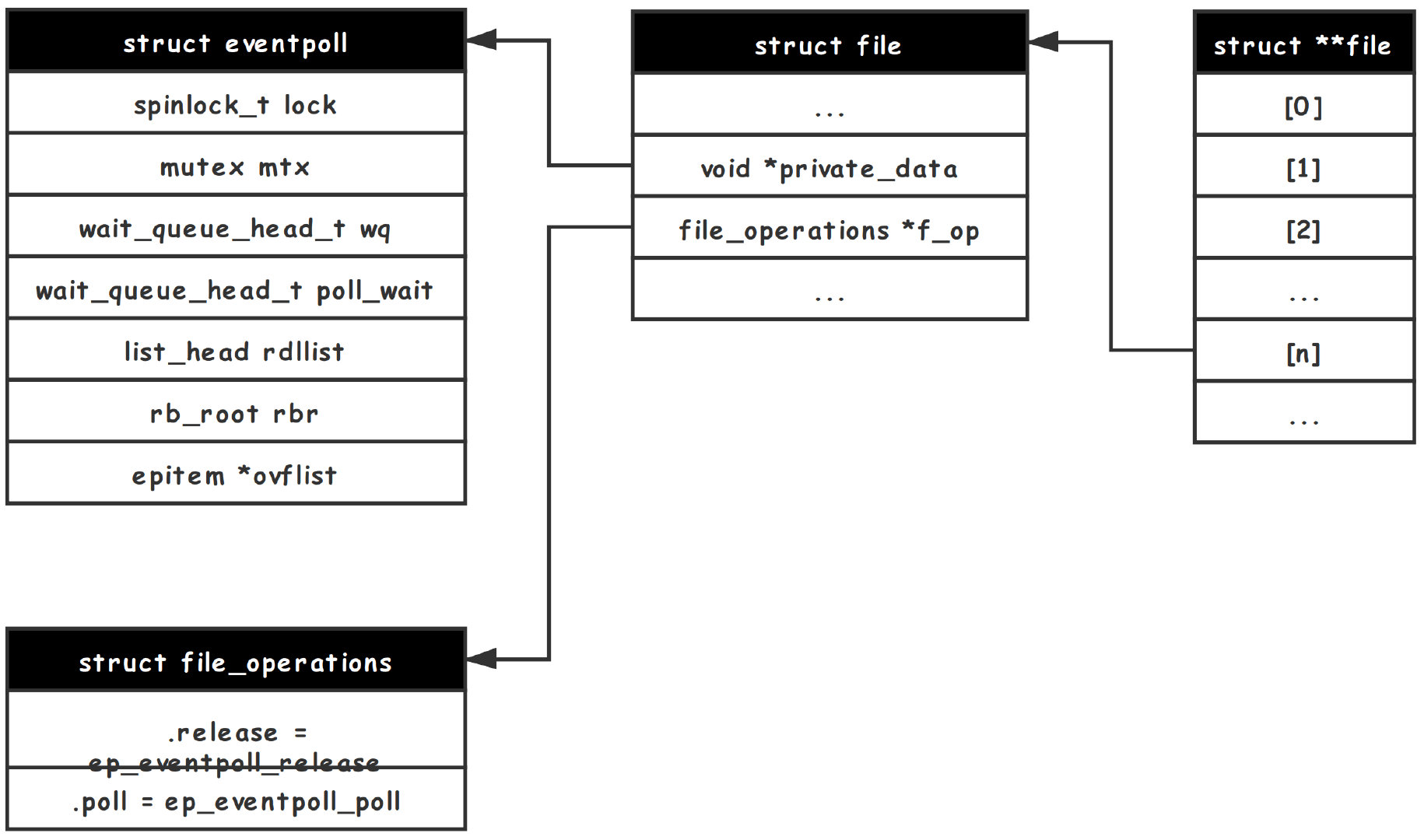
epoll_ctl
epoll_ctl 顾名思义——epoll控制器,用于增加、修改、删除监听的事件。这里 epfd 用于找到 eventpoll 实例,fd 表示需要监听的文件描述符,op 区分增删改,event 表示监听的具体事件描述。
asmlinkage long sys_epoll_ctl(int epfd, int op, int fd,
struct epoll_event __user *event)
{
int error;
struct file *file, *tfile;
struct eventpoll *ep;
struct epitem *epi;
struct epoll_event epds;
DNPRINTK(3, (KERN_INFO "[%p] eventpoll: sys_epoll_ctl(%d, %d, %d, %p)\n",
current, epfd, op, fd, event));
error = -EFAULT;
/* 如果是增改操作,需要把事件描述拷贝到内核数据区; 删除操作不需要 */
if (ep_op_has_event(op) &&
copy_from_user(&epds, event, sizeof(struct epoll_event)))
goto error_return;
/* Get the "struct file *" for the eventpoll file */
error = -EBADF;
file = fget(epfd);
if (!file)
goto error_return;
/* Get the "struct file *" for the target file */
tfile = fget(fd);
if (!tfile)
goto error_fput;
/* 需要监听的文件描述符必须支持文件操作 poll */
error = -EPERM;
if (!tfile->f_op || !tfile->f_op->poll)
goto error_tgt_fput;
/* 需要确保不能把epfd作为被监听的fd加入 */
error = -EINVAL;
if (file == tfile || !is_file_epoll(file))
goto error_tgt_fput;
/*
* 这里的文件描述符一定是指eventpoll实例对应的文件描述符
* 因此直接从中拿私有数据--预定义的*eventpoll
*/
ep = file->private_data;
mutex_lock(&ep->mtx);
/*
* 从RB树中查找已经维护起来的监听事件
* 当然,必须先把这个RB树结构锁定,防止查找时结构改变
*/
epi = ep_find(ep, tfile, fd);
error = -EINVAL;
switch (op) {
case EPOLL_CTL_ADD: // 新增监听
if (!epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_insert(ep, &epds, tfile, fd);
} else
error = -EEXIST;
break;
case EPOLL_CTL_DEL: // 删除监听
if (epi)
error = ep_remove(ep, epi);
else
error = -ENOENT;
break;
case EPOLL_CTL_MOD: // 修改监听
if (epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_modify(ep, epi, &epds);
} else
error = -ENOENT;
break;
}
mutex_unlock(&ep->mtx);
error_tgt_fput:
fput(tfile);
error_fput:
fput(file);
error_return:
DNPRINTK(3, (KERN_INFO "[%p] eventpoll: sys_epoll_ctl(%d, %d, %d, %p) = %d\n",
current, epfd, op, fd, event, error));
return error;
}
这里的核心操作,就是往 eventpoll 实例中增删改监听的事件。以 ep_insert 为例,先看看怎么新增监听。
/* 实例化 epitem */
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))
goto error_return;
/* 对 epitem 实例进行初始化数据 */
ep_rb_initnode(&epi->rbn);
INIT_LIST_HEAD(&epi->rdllink);
INIT_LIST_HEAD(&epi->fllink);
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
/* 构建struct epoll_filefd,作为rb_tree比较不同的key */
ep_set_ffd(&epi->ffd, tfile, fd);
epi->event = *event;
epi->nwait = 0;
epi->next = EP_UNACTIVE_PTR;
接下来要接触的就是一段比较烧脑的逻辑。
poll_table 是在 VFS 实现中相当重要的一个数据结构,用来与poll配合(这里的poll是指文件操作中的,而不是poll()系统调用)
typedef struct poll_table_struct {
poll_queue_proc _qproc;
} poll_table;
其中poll_queue_proc是一个函数指针
typedef void (*poll_queue_proc)(struct file *, wait_queue_head_t *, struct poll_table_struct *);
为了让 epitem 更方便地追踪 poll_queue_proc,epoll_ctl 中使用了一个 ep_pqueue 的数据结构来包装 poll_table。
/* 使用 queue 回调函数初始化 poll table */
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
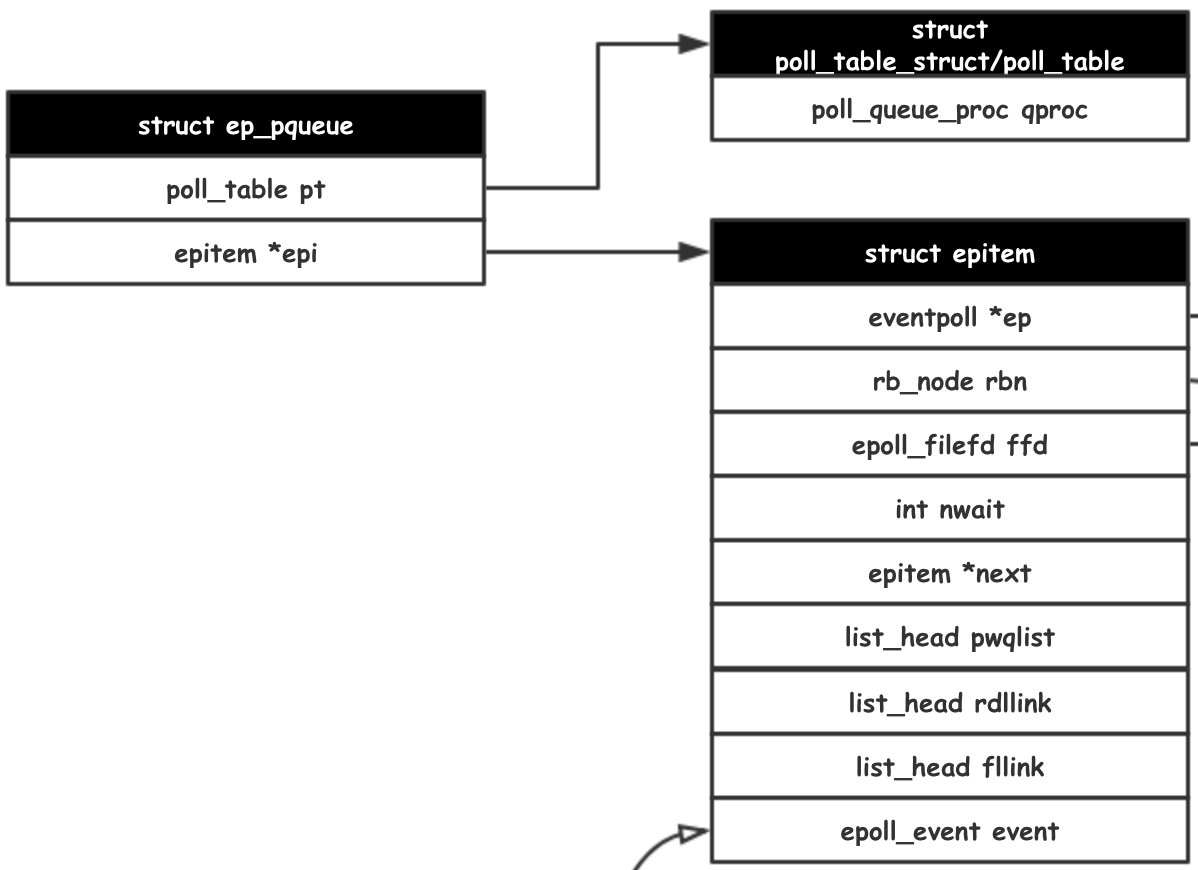
之后就是把这个 poll_table 作为钩子方法挂载到被监控的文件上
revents = tfile->f_op->poll(tfile, &epq.pt);
这里以 tcp_poll 为例,先看看这段逻辑怎么实现的。
static unsigned int sock_poll(struct file *file, poll_table *wait)
{
struct socket *sock;
/* 获取 struct sock 内核套接字数据结构 */
sock = file->private_data;
return sock->ops->poll(file, sock, wait);
}
unsigned int tcp_poll(struct file *file, struct socket *sock, poll_table *wait)
{
unsigned int mask;
struct sock *sk = sock->sk;
struct tcp_sock *tp = tcp_sk(sk);
/*
* 这里将调用 poll_table *wait 维护的回调函数
* 将持有 eventpoll 实例的进程注册到 sk 的等待队列中
*/
poll_wait(file, sk->sk_sleep, wait);
if (sk->sk_state == TCP_LISTEN)
return inet_csk_listen_poll(sk);
/*
* 这里省略了部分逻辑,主要是负责处理 struct sock 接收到的事件
* 处理成 mask 并返回
*/
...
return mask;
}
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && wait_address)
p->qproc(filp, wait_address, p);
}
再来看看epoll定义的回调函数的实现。
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
pwq->whead = whead;
pwq->base = epi;
/* 添加到 struct sock 等待队列队首 */
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}
到此为止,ep_insert 核心的逻辑已经介绍完毕。主要就是将当前的 eventpoll 实例注册到监听目标(文件描述符)的等待队列上,并注册ep_poll_callback作为回调函数。回调函数实现是怎样呢?
static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
int pwake = 0;
unsigned long flags;
/* 获取 wait 结构维护的 epitem 实例 */
struct epitem *epi = ep_item_from_wait(wait);
struct eventpoll *ep = epi->ep;
// ... code omitted...
/*
* 把当前的 epitem 实例添加到 eventpoll 实例的就绪队列中
* 这是显然的,毕竟此回调函数只有在fd准备就绪后被回调
*/
list_add_tail(&epi->rdllink, &ep->rdllist);
is_linked:
/* 如果 wait 结构维护的进程处于Sleeping状态,则将其唤醒并加入任务就绪队列 */
if (waitqueue_active(&ep->wq))
__wake_up_locked(&ep->wq, TASK_UNINTERRUPTIBLE |
TASK_INTERRUPTIBLE);
if (waitqueue_active(&ep->poll_wait))
pwake++;
out_unlock:
spin_unlock_irqrestore(&ep->lock, flags);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&psw, &ep->poll_wait);
return 1;
}
epoll_wait
处理完所有的监听事件的维护,用户程序需要通过 epoll_wait 与 eventpoll 实例进行交互,并被告知所有正在监听中的事件是否发生。由于 epoll_wait 的整个逻辑基本上都是在进行错误检测,此处不表。我们只关注其中的核心逻辑,即调用的 ep_poll 函数。
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
int res, eavail;
unsigned long flags;
long jtimeout;
wait_queue_t wait;
/*
* Calculate the timeout by checking for the "infinite" value ( -1 )
* and the overflow condition. The passed timeout is in milliseconds,
* that why (t * HZ) / 1000.
*/
jtimeout = (timeout < 0 || timeout >= EP_MAX_MSTIMEO) ?
MAX_SCHEDULE_TIMEOUT : (timeout * HZ + 999) / 1000;
retry:
spin_lock_irqsave(&ep->lock, flags);
res = 0;
/*
* 如果 eventpoll 实例的就绪队列为空,表明有没任何监听的事件发生。
* 主动让进程陷入Sleeping状态,知道被 ep_poll_callback() 唤醒
*/
if (list_empty(&ep->rdllist)) {
init_waitqueue_entry(&wait, current);
wait.flags |= WQ_FLAG_EXCLUSIVE;
__add_wait_queue(&ep->wq, &wait);
for (;;) {
/*
* We don't want to sleep if the ep_poll_callback() sends us
* a wakeup in between. That's why we set the task state
* to TASK_INTERRUPTIBLE before doing the checks.
*/
set_current_state(TASK_INTERRUPTIBLE);
if (!list_empty(&ep->rdllist) || !jtimeout)
break;
if (signal_pending(current)) {
res = -EINTR;
break;
}
spin_unlock_irqrestore(&ep->lock, flags);
/* 主动陷入Sleeping状态 */
jtimeout = schedule_timeout(jtimeout);
spin_lock_irqsave(&ep->lock, flags);
}
__remove_wait_queue(&ep->wq, &wait);
set_current_state(TASK_RUNNING);
}
/* Is it worth to try to dig for events ? */
eavail = !list_empty(&ep->rdllist);
spin_unlock_irqrestore(&ep->lock, flags);
/*
* 将监听到的事件拷贝到用户空间。如果没有事件就绪且还没超时,就再抱着
* 希望试一次。
*/
if (!res && eavail &&
!(res = ep_send_events(ep, events, maxevents)) && jtimeout)
goto retry;
return res;
}
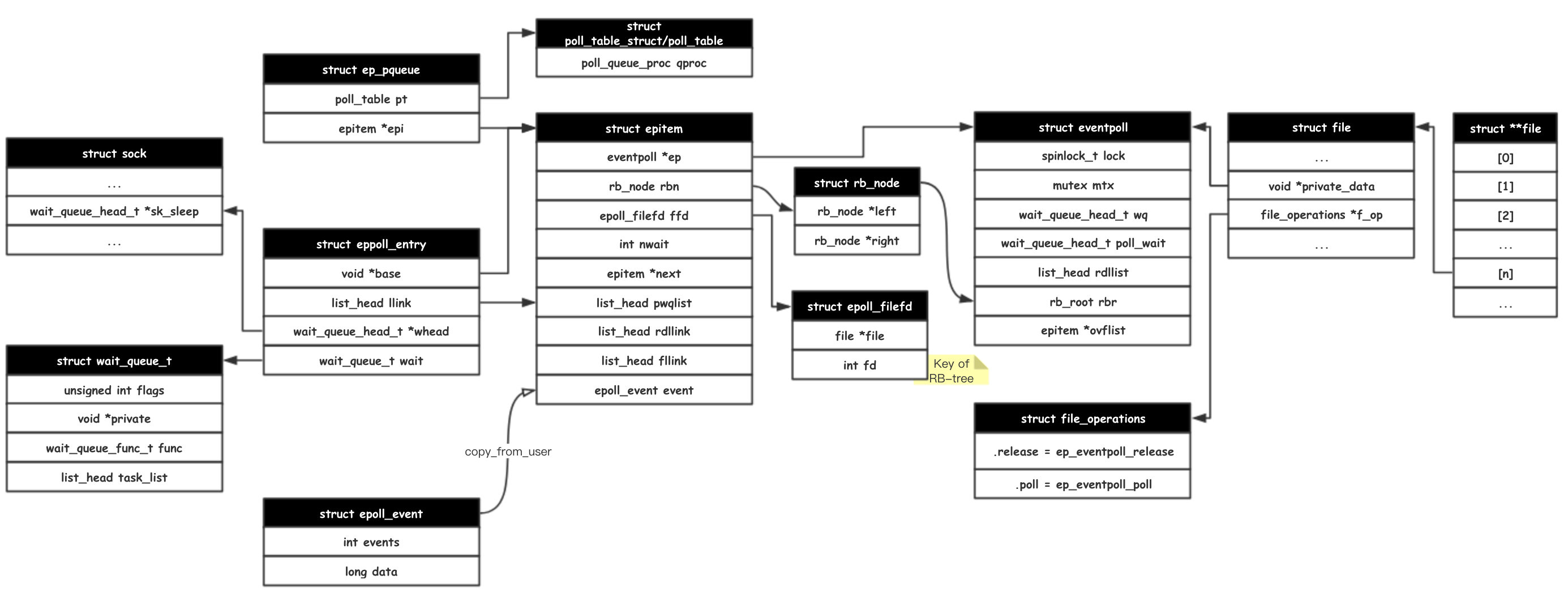
Extra
这部分的数据结构配合着一些胶水代码比较难以理解,最好配合着类图看看(个人使用,不一定适合各位)
参考
- Linux Kernel 2.6.24
- The Implementation of epoll(1)
- The Implementation of epoll(2)
- The Implementation of epoll(3)
- The Implementation of epoll(4)
__ __
/ _| __ _ _ __ __ _ / _| ___ _ __ __ _
| |_ / _` | '_ \ / _` | |_ / _ \ '_ \ / _` |
| _| (_| | | | | (_| | _| __/ | | | (_| |
|_| \__,_|_| |_|\__, |_| \___|_| |_|\__, |
|___/ |___/