几乎每个进程都有独立的虚拟地址空间,这是一个逻辑上的概念,用于建立进程对进程存储资源的认知。对于 32 位机,虚拟地址空间的大小通常是 4GB;对于 64 位机,最大可以达到 $2^{64}$ Bytes 。
本篇便是为了看看虚拟地址空间究竟如何被内核管理,又是怎样和物理内存、文件等资源关联。
启动新进程
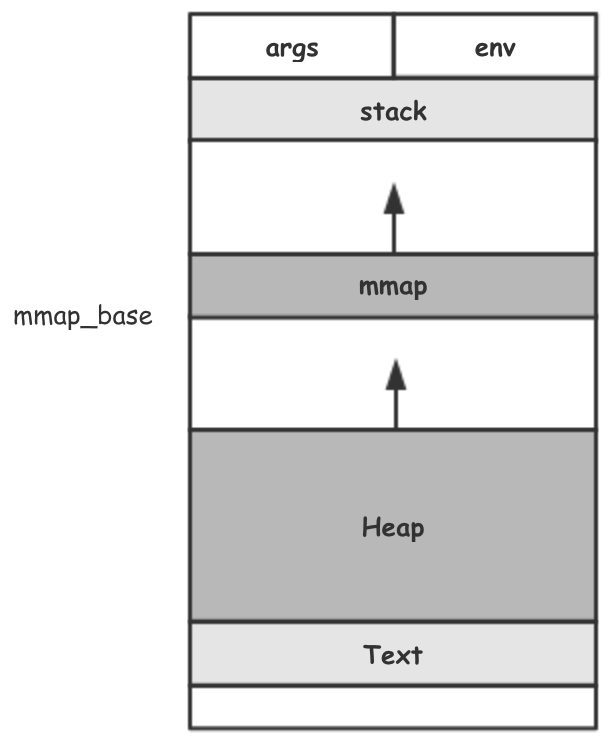
虚拟地址空间与进程挂钩,在进程数据结构 task_struct 中由一个重要的参数 mm_struct 来维护。
struct mm_struct {
struct vm_area_struct * mmap; /* list of VMAs */
struct rb_root mm_rb;
unsigned long mmap_base; /* base of mmap area */
unsigned long task_size; /* size of task vm space */
pgd_t * pgd;
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
int map_count; /* number of VMAs */
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
struct file *exe_file;
/* ... some code omitted ... */
};
start_code, end_code 描述的是任务的可执行文件在虚拟内存地址中所处的区间。start_data, end_data 描述可执行文件的数据段,通常情况下与 start_code, end_code 指向同一段,只不过 rwx 的权限控制不同罢了。
start_brk 和 brk 共同描述堆的起末点,通过 syscall brk 可以调整 brk 的值,也就是在运行过程中调整堆的大小。
arg_start, arg_end, env_start, env_end 分别描述命令参数和环境变量在虚拟内存地址中所处的位置。
新任务的启动,通常是通过 fork, clone 等系统调用拷贝父任务几乎所有的状态和资源指针,然后通过 execve 系统调用替换可执行文件,重置虚拟内存等其他相关资源。
/* Hint: 省略了一些无关代码 */
/* execve 系统调用的入口 */
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
struct filename *path = getname(filename);
error = do_execve(path->name, argv, envp);
putname(path);
return error;
}
int do_execve(const char *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execve_common(filename, argv, envp);
}
static int do_execve_common(const char *filename,
struct user_arg_ptr argv,
struct user_arg_ptr envp)
{
// 检测 ulimit 限制的进程总数
// 选择合适的 CPU 核以运行新任务
sched_exec();
// 建立一个临时的栈内存来支持任务启动
retval = bprm_mm_init(bprm);
bprm->argc = count(argv, MAX_ARG_STRINGS);
bprm->envc = count(envp, MAX_ARG_STRINGS);
retval = prepare_binprm(bprm);
// 从用户空间拷贝字符串 (可执行文件路径、环境变量、启动参数)
retval = copy_strings_kernel(1, &bprm->filename, bprm);
retval = copy_strings(bprm->envc, envp, bprm);
retval = copy_strings(bprm->argc, argv, bprm);
// 根据可执行文件的格式,选择合适的加载函数 (例如 load_elf_binary)
retval = search_binary_handler(bprm);
/* execve succeeded */
current->fs->in_exec = 0;
current->in_execve = 0;
acct_update_integrals(current);
free_bprm(bprm);
if (displaced)
put_files_struct(displaced);
return retval;
}
整体而言,execve 在完成了大量 check 的工作之后,把核心的加载流程委托给特定于可执行文件的加载模块来完成。以 ELF 文件格式为例,整体流程如下:
|-- sys_execve
|-- do_execve
|-- do_execve_common
|-- sched_exec
|-- bprm_mm_init
|-- prepare_binprm
|-- kernel_read
|-- search_binary_handler
|-- load_elf_binary
|-- acct_update_integrals
/* From fs/binfmt_elf.c */
static int load_elf_binary(struct linux_binprm *bprm)
{
/* 获取可执行文件的头 128 B,已经由 kernel_read 提前读取到内存了 */
loc->elf_ex = *((struct elfhdr *)bprm->buf);
/* 确认是否是 ELF 文件格式,比较文件格式魔数。#define ELFMAG "\177ELF" */
if (memcmp(loc->elf_ex.e_ident, ELFMAG, SELFMAG) != 0)
goto out;
if (loc->elf_ex.e_type != ET_EXEC && loc->elf_ex.e_type != ET_DYN)
goto out;
if (!elf_check_arch(&loc->elf_ex))
goto out;
if (!bprm->file->f_op || !bprm->file->f_op->mmap)
goto out;
/* 读取所有的 elf header data */
retval = kernel_read(bprm->file, loc->elf_ex.e_phoff,
(char *)elf_phdata, size);
/* 设置新的可执行文件结构 */
setup_new_exec(bprm);
/* 在虚拟地址空间设置启动参数 */
retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP),
executable_stack);
current->mm->start_stack = bprm->p;
/* 将 ELF text、code、bss 段等迁移到虚拟地址空间合适的位置 */
/* 设置 brk 的位置 */
retval = set_brk(elf_bss, elf_brk);
/* 设置 mm_struct 关于 text、data、stack 的参数 */
current->mm->end_code = end_code;
current->mm->start_code = start_code;
current->mm->start_data = start_data;
current->mm->end_data = end_data;
current->mm->start_stack = bprm->p;
#ifdef arch_randomize_brk
if ((current->flags & PF_RANDOMIZE) && (randomize_va_space > 1)) {
current->mm->brk = current->mm->start_brk =
arch_randomize_brk(current->mm);
#ifdef CONFIG_COMPAT_BRK
current->brk_randomized = 1;
#endif
}
#endif
start_thread(regs, elf_entry, bprm->p);
retval = 0;
}
/* From fs/exec.c */
void setup_new_exec(struct linux_binprm * bprm)
{
/* 根据 CPU 架构选择 mmap 布局方式 */
arch_pick_mmap_layout(current->mm);
/* 配置信号栈 */
current->sas_ss_sp = current->sas_ss_size = 0;
set_task_comm(current, bprm->tcomm);
current->mm->task_size = TASK_SIZE;
current->self_exec_id++;
flush_signal_handlers(current, 0);
do_close_on_exec(current->files);
}
/* From arch/x86/mm/mmap.c */
void arch_pick_mmap_layout(struct mm_struct *mm)
{
if (mmap_is_legacy()) {
mm->mmap_base = mmap_legacy_base();
mm->get_unmapped_area = arch_get_unmapped_area;
mm->unmap_area = arch_unmap_area;
} else {
/* 新的 mmap 是从靠近 stack 的高地址开始,向低地址延伸的 */
mm->mmap_base = mmap_base();
mm->get_unmapped_area = arch_get_unmapped_area_topdown;
mm->unmap_area = arch_unmap_area_topdown;
}
}
从传统的 mmap 配置方式,mmap_base 被配置为 TASK_SIZE / 3 。在 x86 32bit CPU 上,TASK_SIZE 通常被配置为 3GB (剩下的 1GB 的虚拟地址空间作为内核空间使用)。在整个 ELF 文件的加载过程中,mm_struct 依照既定的值或者经由计算得到的值被逐一填充。组成了一段涵盖可执行文件代码段、数据段、堆、栈、mmap 区域等的虚拟内存空间。
堆的增长
抛却我们所熟知的 malloc、free 等内存申请与释放函数。从 mm_struct 可以看到三块可用的内存区域——堆、mmap 区域、栈。
堆的增长与缩减通过 brk, sbrk 两个系统调用来完成。
SYSCALL_DEFINE1(brk, unsigned long, brk)
{
/* Ok, looks good - let it rip. */
if (do_brk(oldbrk, newbrk-oldbrk) != oldbrk)
goto out;
}
/* From mm/mmap.c */
static unsigned long do_brk(unsigned long addr, unsigned long len)
{
struct mm_struct * mm = current->mm;
struct vm_area_struct * vma, * prev;
unsigned long flags;
struct rb_node ** rb_link, * rb_parent;
pgoff_t pgoff = addr >> PAGE_SHIFT;
int error;
len = PAGE_ALIGN(len);
if (!len)
return addr;
flags = VM_DATA_DEFAULT_FLAGS | VM_ACCOUNT | mm->def_flags;
error = get_unmapped_area(NULL, addr, len, 0, MAP_FIXED);
if (error & ~PAGE_MASK)
return error;
/* 锁,保证同一时间只有一个任务在操作虚拟内存空间分配 */
verify_mm_writelocked(mm);
/*
* Clear old maps. this also does some error checking for us
*/
munmap_back:
if (find_vma_links(mm, addr, addr + len, &prev, &rb_link, &rb_parent)) {
if (do_munmap(mm, addr, len))
return -ENOMEM;
goto munmap_back;
}
/* Check against address space limits *after* clearing old maps... */
if (!may_expand_vm(mm, len >> PAGE_SHIFT))
return -ENOMEM;
if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;
if (security_vm_enough_memory_mm(mm, len >> PAGE_SHIFT))
return -ENOMEM;
/* Can we just expand an old private anonymous mapping? */
vma = vma_merge(mm, prev, addr, addr + len, flags,
NULL, NULL, pgoff, NULL);
if (vma)
goto out;
/* 创建一个新的匿名映射结构,brk 说到底就是一种特殊的 mmap */
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
if (!vma) {
vm_unacct_memory(len >> PAGE_SHIFT);
return -ENOMEM;
}
/* 向 vma 列表添加新的虚拟内存段记录 */
INIT_LIST_HEAD(&vma->anon_vma_chain);
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_pgoff = pgoff;
vma->vm_flags = flags;
vma->vm_page_prot = vm_get_page_prot(flags);
vma_link(mm, vma, prev, rb_link, rb_parent);
out:
perf_event_mmap(vma);
mm->total_vm += len >> PAGE_SHIFT;
if (flags & VM_LOCKED)
mm->locked_vm += (len >> PAGE_SHIFT);
return addr;
}
mm_struct 通过 brk 参数维护了堆的边界,brk 系统调用的作用就是对这个参数进行调整,从而让任务所能够使用的虚拟内存扩大。另一方面,这个 brk 的实现就等同于是 mmap 的一个压缩版,只是去掉了对文件等内容的直接映射罢了(mmap 的实现稍后呈现)。
匿名地址空间映射
mmap 一直被描述为一种直接内存映射文件的方式,区别于 read, write ,对它的核心定义就是高效。
通常来说,读写都涉及到至少 2 次内存间的数据拷贝。
- 磁盘与内存缓冲区之间的数据拷贝
- 内核数据区与用户数据区之间的数据拷贝
内核暴露了两种 mmap 系统调用的接口,根据处理器架构的不同,做了不同的适配实现,一般来说都是一种实现委托另一种的形式。这里以 x86 为例。
SYSCALL_DEFINE1(old_mmap, struct mmap_arg_struct __user *, arg)
{
struct mmap_arg_struct a;
if (copy_from_user(&a, arg, sizeof(a)))
return -EFAULT;
if (a.offset & ~PAGE_MASK)
return -EINVAL;
// 委托 mmap_pgoff 来实现
return sys_mmap_pgoff(a.addr, a.len, a.prot, a.flags, a.fd,
a.offset >> PAGE_SHIFT);
}
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
struct file *file = NULL;
unsigned long retval = -EBADF;
if (!(flags & MAP_ANONYMOUS)) {
// 非匿名映射,意味着一定与文件做映射(这是广义上的文件)
// ... some code omitted ...
file = fget(fd);
} else if (flags & MAP_HUGETLB) {
// 使用大内存页
// ... some code omitted ...
}
flags &= ~(MAP_EXECUTABLE | MAP_DENYWRITE);
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
if (file)
fput(file);
return retval;
}
vm_mmap_pgoff 是一个 wrapper,来构建临界区代码
unsigned long vm_mmap_pgoff(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flag, unsigned long pgoff)
{
unsigned long ret;
struct mm_struct *mm = current->mm;
unsigned long populate;
ret = security_mmap_file(file, prot, flag);
if (!ret) {
down_write(&mm->mmap_sem);
// 临界区
ret = do_mmap_pgoff(file, addr, len, prot, flag, pgoff,
&populate);
up_write(&mm->mmap_sem);
if (populate)
mm_populate(ret, populate);
}
return ret;
}
do_mmap_pgoff 基于 flags 进行了大量的检查工作,确保 mmap 得到可靠的映射结果。其核心的逻辑又是分别依赖于函数 get_unmapped_area 和 mmap_region。
unsigned long do_mmap_pgoff(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, unsigned long pgoff,
unsigned long *populate)
{
struct mm_struct * mm = current->mm;
struct inode *inode;
vm_flags_t vm_flags;
*populate = 0;
if (!(flags & MAP_FIXED))
// 低于 vm addr 硬下限,改成一个可用的最小地址
addr = round_hint_to_min(addr);
// 地址对齐
len = PAGE_ALIGN(len);
// 规避地址溢出的问题
if ((pgoff + (len >> PAGE_SHIFT)) < pgoff)
return -EOVERFLOW;
// 达到系统参数 mmap 映射数上限?
if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;
// 取一个未被映射的地址
addr = get_unmapped_area(file, addr, len, pgoff, flags);
// 地址对齐
if (addr & ~PAGE_MASK)
return addr;
vm_flags = calc_vm_prot_bits(prot) | calc_vm_flag_bits(flags) |
mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
// MLOCK 相关操作,如果置位,可以保持映射的物理内存块不会被移出内存
inode = file ? file_inode(file) : NULL;
if (file) {
switch (flags & MAP_TYPE) {
case MAP_SHARED: // 共享标志,此时对文件内容的修改对其它任务可见
if ((prot&PROT_WRITE) && !(file->f_mode&FMODE_WRITE))
return -EACCES;
if (IS_APPEND(inode) && (file->f_mode & FMODE_WRITE))
return -EACCES;
// 确保此文件未被其它任务锁定
if (locks_verify_locked(inode))
return -EAGAIN;
vm_flags |= VM_SHARED | VM_MAYSHARE;
if (!(file->f_mode & FMODE_WRITE))
vm_flags &= ~(VM_MAYWRITE | VM_SHARED);
/* fall through */
case MAP_PRIVATE:
if (!(file->f_mode & FMODE_READ))
return -EACCES;
if (file->f_path.mnt->mnt_flags & MNT_NOEXEC) {
if (vm_flags & VM_EXEC)
return -EPERM;
vm_flags &= ~VM_MAYEXEC;
}
if (!file->f_op || !file->f_op->mmap)
return -ENODEV;
break;
default:
return -EINVAL;
}
} else {
switch (flags & MAP_TYPE) {
case MAP_SHARED: // 共享标志,此时对这段内存内容的修改对其它任务可见
// 因此不能有偏移量
pgoff = 0;
vm_flags |= VM_SHARED | VM_MAYSHARE;
break;
case MAP_PRIVATE:
pgoff = addr >> PAGE_SHIFT;
break;
default:
return -EINVAL;
}
}
addr = mmap_region(file, addr, len, vm_flags, pgoff);
return addr;
}
get_unmapped_area 负责从虚拟地址空间中寻找一块合适的空间用于映射。根据是否指定 addr,是否做文件映射,分别又走向不同的逻辑分支。具体实现不再细数。函数的执行结果,就是得到可用的起始地址信息。
mmap_region 做的是维护一个新的 vma 数据结构。根据实际场景,会涉及到释放冲突的 mmap 区域,合并直接衔接的 mmap 区块,更新映射文件的信息等。最终会将新的 vma 添加到 mm_struct 维护的红黑树及链表中。额外的,还有一些统计的工作,以及内存超卖等的策略实施。
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
int correct_wcount = 0;
int error;
struct rb_node **rb_link, *rb_parent;
unsigned long charged = 0;
struct inode *inode = file ? file_inode(file) : NULL;
error = -ENOMEM;
/* 如果新的 mmap 区域早已经被映射,则释放掉老的映射 */
munmap_back:
if (find_vma_links(mm, addr, addr + len, &prev, &rb_link, &rb_parent)) {
if (do_munmap(mm, addr, len))
return -ENOMEM;
goto munmap_back;
}
/*
* 确认物理内存是否足够用于支撑虚拟内存
* 根据不同的 overcommit (内存超卖) 策略会有不同的结论。
*/
if (accountable_mapping(file, vm_flags)) {
charged = len >> PAGE_SHIFT;
if (security_vm_enough_memory_mm(mm, charged))
return -ENOMEM;
vm_flags |= VM_ACCOUNT;
}
/* 如果新的映射区域能与老的映射区域相连,则合并两个映射区域*/
vma = vma_merge(mm, prev, addr, addr + len, vm_flags, NULL, file, pgoff, NULL);
if (vma) // 如果能合并,则跳到 out 处
goto out;
// 为 vma 结构申请一块内存
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
INIT_LIST_HEAD(&vma->anon_vma_chain);
error = -EINVAL; /* when rejecting VM_GROWSDOWN|VM_GROWSUP */
/* 如果做文件映射,需要额外地维护文件的结构,声明其与一块 mmap 区域关联 */
if (file) {
if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
goto free_vma;
if (vm_flags & VM_DENYWRITE) {
error = deny_write_access(file);
if (error)
goto free_vma;
correct_wcount = 1;
}
vma->vm_file = get_file(file);
error = file->f_op->mmap(file, vma);
if (error)
goto unmap_and_free_vma;
WARN_ON_ONCE(addr != vma->vm_start);
addr = vma->vm_start;
pgoff = vma->vm_pgoff;
vm_flags = vma->vm_flags;
} else if (vm_flags & VM_SHARED) {
if (unlikely(vm_flags & (VM_GROWSDOWN|VM_GROWSUP)))
goto free_vma;
error = shmem_zero_setup(vma);
if (error)
goto free_vma;
}
// 将新的 vma 结构维护到 mm 红黑树及链表上
vma_link(mm, vma, prev, rb_link, rb_parent);
file = vma->vm_file;
/* Once vma denies write, undo our temporary denial count */
if (correct_wcount)
atomic_inc(&inode->i_writecount);
out:
perf_event_mmap(vma);
vm_stat_account(mm, vm_flags, file, len >> PAGE_SHIFT);
if (vm_flags & VM_LOCKED) {
if (!((vm_flags & VM_SPECIAL) || is_vm_hugetlb_page(vma) ||
vma == get_gate_vma(current->mm)))
mm->locked_vm += (len >> PAGE_SHIFT);
else
vma->vm_flags &= ~VM_LOCKED;
}
if (file)
uprobe_mmap(vma);
return addr;
}
到此为止,基本上一个新的 mmap 区域的申请就完成了。不过,由于内核内存管理模块将缺页等操作提取并后置,这里都没有看到操作物理内存,只有逻辑上的为申请的虚拟内存划分区域,记录状态。不过,这恰恰也是内核高效的一个体现。如果申请虚拟内存直接跟物理内存挂钩,首先是两类内存逻辑上的耦合,其次是过度浪费(申请和使用通常是割裂的,再就是有时是申请了但不会进行使用),再次就是效率了。所以,很多时候写惯了 C 代码,用 malloc 大量申请内存,却看到系统的可用内存几乎没有变化,就是这个道理;另外 Java 堆的申请也类似于这种,如果申请了 2GB 的 Java 堆,一般来说从内核来看,是申请了 2 GB 大小的 anon mmap 区域,初始是不会与物理内存挂钩,等到 GC 发生时,会发现即使清理了垃圾,系统可用内存还是没有增加(这是 2GB 都处于 JVM 管理之下了,虽然从虚拟机看来已经清理出了内存,但系统并不会意识到这一点)
小结
关于虚拟内存,还有相当多的内容等待揭开。比如文件映射中如何保证内存中的文件与磁盘中的文件的高效同步;不同策略下内存超卖的表现;缺页场景下虚拟内存与物理内存的映射…
浅尝,后续有时间再继续翻看。