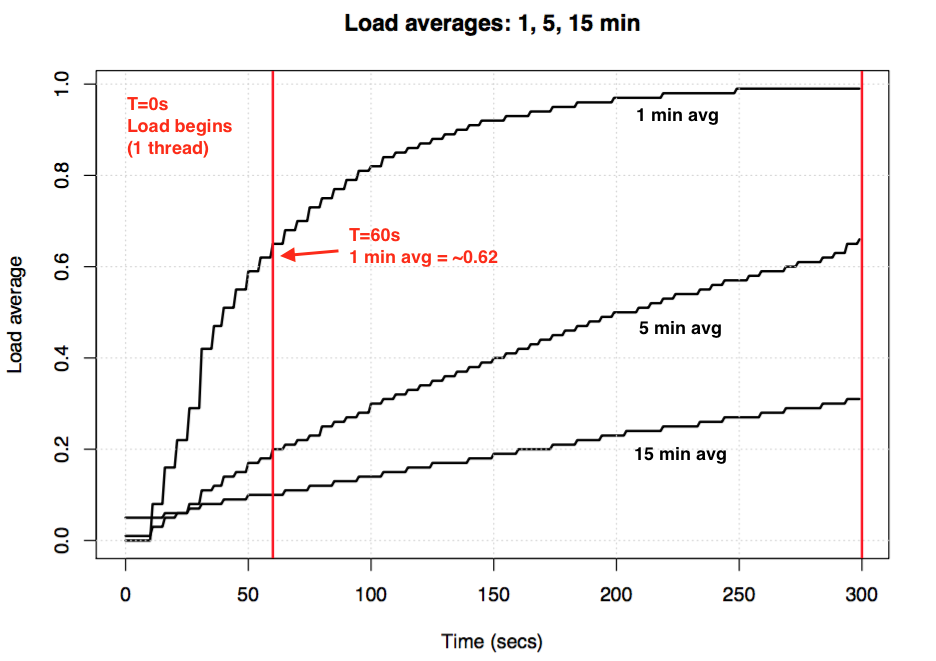
Load Average 是监控系统负载的重要指标。但是,在最近的测试中,使用简单的 CPU 密集型程序执行 1 分钟,系统 1 分钟的平均负载却只能达到 0.63。
ffutop $ time ./a
./a 59.48s user 0.04s system 98% cpu 1:00.59 total
ffutop $ uptime
09:58:56 up 165 days, 20:14, 2 users, load average: 0.63, 0.24, 0.09
是什么原因导致平均负载与预期值不符呢?
/proc/loadavg
通过对 strace 的分析,系统平均负载的数据来源于 /proc 虚拟文件系统下的文件 loadavg。
ffutop $ strace uptime
# ... some thing omitted ...
openat(AT_FDCWD, "/proc/loadavg", O_RDONLY) = 4
lseek(4, 0, SEEK_SET) = 0
read(4, "0.00 0.01 0.00 3/245 32222\n", 8191) = 27
fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 0), ...}) = 0
write(1, " 10:24:25 up 165 days, 20:39, 2"..., 72 10:24:25 up 165 days, 20:39, 2 users, load average: 0.00, 0.01, 0.00
# ...
打印 loadavg 的内容,总共 5 项结果。
cat /proc/loadavg
0.02 0.03 0.01 1/244 32408
- 前三个数代表 1/5/15 分钟内的系统平均负载,包含所有处于就绪(Running) 和不可中断睡眠(Uninterruptible Sleep) 状态的任务。
- “1/244” 代表当前 1 个任务处于就绪状态,总共有 244 个任务。
- “32408” 表示最近一次分配的任务 PID 编号。
背后的内核函数是 loadavg_proc_show
avenrun 统计值
/* From fs/proc/loadavg.c */
static int loadavg_proc_show(struct seq_file *m, void *v)
{
unsigned long avnrun[3];
get_avenrun(avnrun, FIXED_1/200, 0);
seq_printf(m, "%lu.%02lu %lu.%02lu %lu.%02lu %ld/%d %d\n",
LOAD_INT(avnrun[0]), LOAD_FRAC(avnrun[0]),
LOAD_INT(avnrun[1]), LOAD_FRAC(avnrun[1]),
LOAD_INT(avnrun[2]), LOAD_FRAC(avnrun[2]),
nr_running(), nr_threads,
task_active_pid_ns(current)->last_pid);
return 0;
}
/* From kernel/sched/core.c */
unsigned long avenrun[3];
void get_avenrun(unsigned long *loads, unsigned long offset, int shift)
{
loads[0] = (avenrun[0] + offset) << shift;
loads[1] = (avenrun[1] + offset) << shift;
loads[2] = (avenrun[2] + offset) << shift;
}
事实上 loadavg_proc_show 也仅仅只是承担将数据按预定格式渲染的职责,真正的数据源是内核全局变量 avenrun 。后者由函数 calc_global_load 负责实时刷新。不过,确切地说是周期性刷新(默认的周期是 5 秒一次)。
注意,全局变量 avenrun 是一个长整型的数组,分别用于维护 1 分钟、5 分钟、15 分钟的平均负载。但是,打印出来的结果分明是浮点数啊!这里内核使用了整数来避免浮点运算带来的性能问题。32 位整型的低 11 位用来表示小数部分,而高位作为整数部分。
如何计算 avenrun ?这里使用了取样的方式,默认是每 5 秒种对各个 CPU 核上处于就绪和不可中断睡眠状态的任务做计数。然后以指数移动平均的方式累积到 avenrun 结果中。
先简单介绍一下朴素的移动平均。假设计算 60 秒的系统平均负载,每 5 秒取样一次,则最近 1 分钟的平均负载:
$$ avenrun[0]_{t} = \frac{load_{t} + load_{t+5} + load_{t+10} + \dots + load_{t+55}}{60 / 5} $$
对于下一个 5 秒的采样结果,使用下列计算公式:
$$ avenrun[0]_{t+5} = avenrun[0]_{t} - \frac{1}{60 / 5} \times load_{t} + \frac{1}{60 / 5} \times load_{t+60} $$
依次类推。移动平均即以类似活动窗口的模式运行,移除最早的采样点对结果的影响,同时添加最新的采样点。
不过,avenrun 使用的移动平均并不太朴素,指数移动平均的描述一般呈现为越早的采样数值对结果的影响越小,呈现指数式的曲线。
$$ avenrun_t = (1 - \beta) \times avenrun_{t-1} + \beta \times load_t $$
至于此处的 $\beta$ ,内核分别使用了 $\frac{2^{11}}{e^{5 / 60}} \approx 1884$ 、$\frac{2^{11}}{e^{5 / 300}} \approx 2014$、$\frac{2^{11}}{e^{5 / 900}} \approx 2037$ 作为 1、5、15 分钟的比例系数。此处的 $2^{11}$ 是用整数计算代替浮点运算带来的倍数(低 11 位代表小数部分)。
#define FSHIFT 11 /* nr of bits of precision */
#define FIXED_1 (1<<FSHIFT) /* 1.0 as fixed-point */
#define LOAD_FREQ (5*HZ+1) /* 5 sec intervals */
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */
#define EXP_5 2014 /* 1/exp(5sec/5min) */
#define EXP_15 2037 /* 1/exp(5sec/15min) */
End
回到最初的问题,几乎跑了 100% CPU 的任务,无法将系统平均负载打到 1.00 也就再正常不过了。虽然从名称上的描述为 1、5、15 分钟的系统平均负载,但事实上,若干分钟前的数据仍然对 1 分钟的平均负载有残留的影响,而这种影响差不多需要 4、5 分钟来消除。