BPF (Berkeley Packet Filter) 相比于其他包过滤技术,最重要的突破就是实现了一种全新的内核态/用户态隔离下的内核数据过滤方案。自由定制的网络监控程序,总是作为用户级程序运行,为完成监控/过滤网络数据包的任务,必然地会涉及到内核空间/用户空间的拷贝。而众所周知的,内核空间/用户空间的拷贝代价极大,特别在大流量的情况下。BPF 的方案,通过部署一个安全的、沙箱化的内核代理直接实现在内核空间下的包过滤(Packet Filter),尽早地将非目标网络包剔除,只对真正有效的目标网络包实施拷贝。
BPF 最早于 1992 年被提出,1997 年起也被 Linux 内核吸收,定名 LSF (Linux Socket Filter, (aka) BPF:)。早期作用仅仅停留在过滤网络报文;在 2013 年由大牛 Alexei Starovoitov 彻底改造形成全新的 eBPF,并开始面向内核跟踪与事件监控、网络编程两大领域展示其强大的功能。
本篇只着眼于传统的 BPF 技术,探求 BPF 如何在内核埋入包过滤相关的钩子以实现其功能。
BPF 代理程序
本节所展示的源码均基于内核版本 2.6.24
既然说 BPF 的高效在于其将一定用户高度个性定制的包过滤代码埋入了内核,那么就先来看看代理程序是如何深入内核,并展开相应的工作。
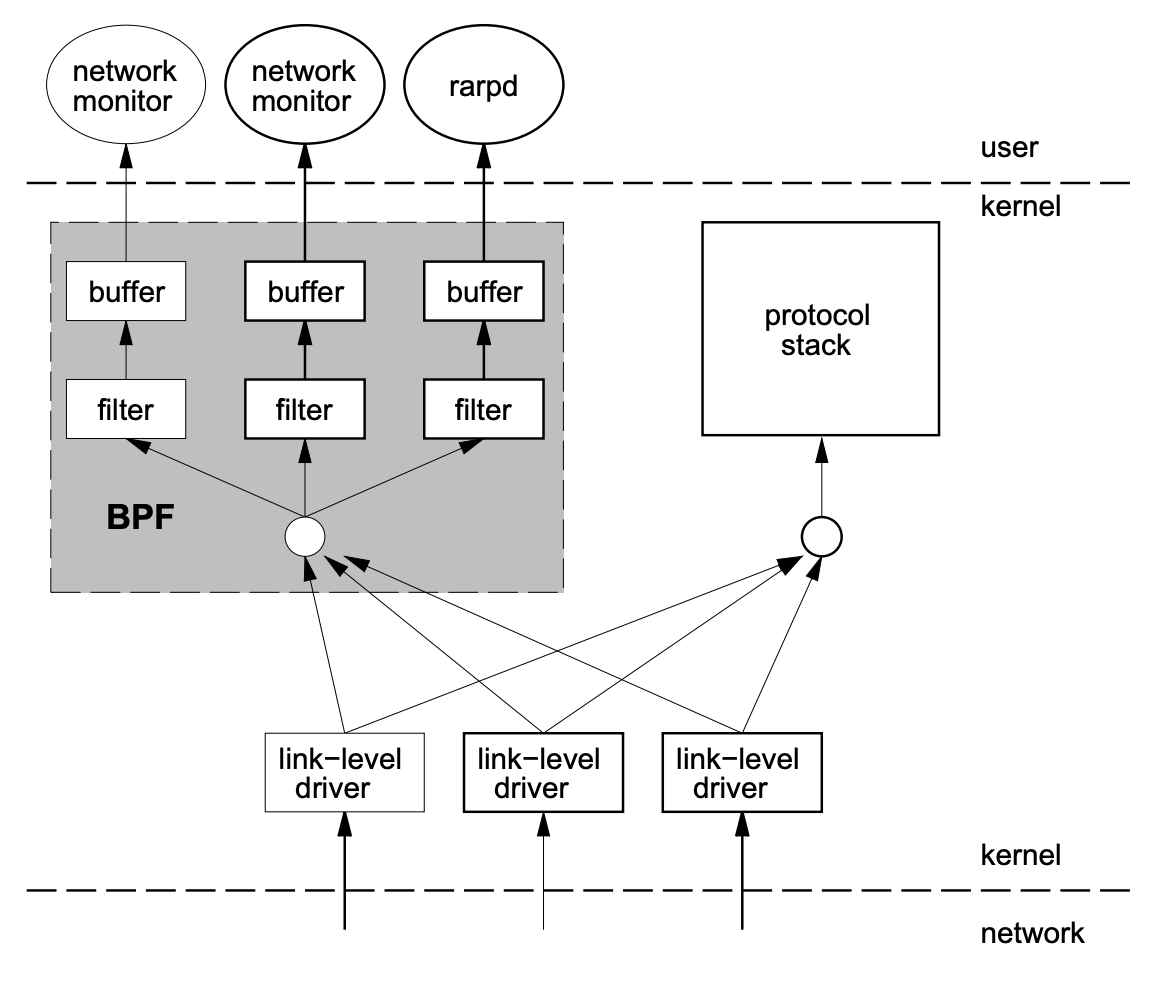
与 BPF 相关的系统调用
socket(AF_PACKET, SOCK_RAW, ...)
bind(sockfd, iface)
setsockopt(sockfd, SOL_SOCKET, SO_ATTACH_FILTER, ...)
recv(sockfd, ...)
通过 setsockopt 系统调用,用户自定义的过滤程序将进入内核空间,并作为钩子对每个通过网络协议栈的网络包进行过滤,抓取并拷贝命中的网络包提交到监听 socket 的接收等待队列中。下列的示例程序展示了配置代理过滤程序及提取过滤结果的逻辑。
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <net/if.h>
#include <net/ethernet.h>
#include <netinet/in.h>
#include <netinet/ip.h>
#include <arpa/inet.h>
#include <netpacket/packet.h>
#include <linux/filter.h>
#define OP_LDH (BPF_LD | BPF_H | BPF_ABS)
#define OP_LDB (BPF_LD | BPF_B | BPF_ABS)
#define OP_JEQ (BPF_JMP | BPF_JEQ | BPF_K)
#define OP_RET (BPF_RET | BPF_K)
static struct sock_filter bpfcode[6] = {
{ OP_LDH, 0, 0, 12 }, // ldh [12]
{ OP_JEQ, 0, 2, ETH_P_IP }, // jeq #0x800, L2, L5
{ OP_LDB, 0, 0, 23 }, // ldb [23]
{ OP_JEQ, 0, 1, IPPROTO_TCP }, // jeq #0x6, L4, L5
{ OP_RET, 0, 0, 0 }, // ret #0x0
{ OP_RET, 0, 0, -1, }, // ret #0xffffffff
};
int main(int argc, char **argv)
{
int sock;
int n;
char buf[2000];
struct sockaddr_ll addr;
struct packet_mreq mreq;
struct iphdr *ip;
char saddr_str[INET_ADDRSTRLEN], daddr_str[INET_ADDRSTRLEN];
char *proto_str;
char *name;
struct sock_fprog bpf = { 6, bpfcode };
if (argc != 2) {
printf("Usage: %s ifname\n", argv[0]);
return 1;
}
name = argv[1];
sock = socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL));
if (sock < 0) {
perror("socket");
return 1;
}
memset(&addr, 0, sizeof(addr));
addr.sll_ifindex = if_nametoindex(name);
addr.sll_family = AF_PACKET;
addr.sll_protocol = htons(ETH_P_ALL);
if (bind(sock, (struct sockaddr *) &addr, sizeof(addr))) {
perror("bind");
return 1;
}
if (setsockopt(sock, SOL_SOCKET, SO_ATTACH_FILTER, &bpf, sizeof(bpf))) {
perror("setsockopt ATTACH_FILTER");
return 1;
}
memset(&mreq, 0, sizeof(mreq));
mreq.mr_type = PACKET_MR_PROMISC;
mreq.mr_ifindex = if_nametoindex(name);
if (setsockopt(sock, SOL_PACKET,
PACKET_ADD_MEMBERSHIP, (char *)&mreq, sizeof(mreq))) {
perror("setsockopt MR_PROMISC");
return 1;
}
for (;;) {
n = recv(sock, buf, sizeof(buf), 0);
if (n < 1) {
perror("recv");
return 0;
}
ip = (struct iphdr *)(buf + sizeof(struct ether_header));
inet_ntop(AF_INET, &ip->saddr, saddr_str, sizeof(saddr_str));
inet_ntop(AF_INET, &ip->daddr, daddr_str, sizeof(daddr_str));
switch (ip->protocol) {
#define PTOSTR(_p,_str) \
case _p: proto_str = _str; break
PTOSTR(IPPROTO_ICMP, "icmp");
PTOSTR(IPPROTO_TCP, "tcp");
PTOSTR(IPPROTO_UDP, "udp");
default:
proto_str = "";
break;
}
printf("IPv%d proto=%d(%s) src=%s dst=%s\n",
ip->version, ip->protocol, proto_str, saddr_str, daddr_str);
}
return 0;
}
setsockopt 作为代理程序进出内核的核心路径。提供 SO_ATTACH_FILTER 和 SO_DETACH_FILTER 两个操作枚举值
/* Copied from net/core/sock.c */
int sock_setsockopt(struct socket *sock, int level, int optname,
char __user *optval, int optlen)
{
struct sock *sk=sock->sk;
int ret = 0;
switch(optname) {
/* some code omitted ... */
case SO_ATTACH_FILTER:
ret = -EINVAL;
if (optlen == sizeof(struct sock_fprog)) {
struct sock_fprog fprog;
ret = -EFAULT;
/* 从用户空间向内核空间拷贝维护着代理程序的通用数据结构 */
if (copy_from_user(&fprog, optval, sizeof(fprog)))
break;
/* 给 sock 挂载上代理程序 */
ret = sk_attach_filter(&fprog, sk);
}
break;
case SO_DETACH_FILTER:
/* 解挂代理程序 */
ret = sk_detach_filter(sk);
break;
default:
ret = -ENOPROTOOPT;
break;
}
release_sock(sk);
return ret;
}
sk_attach_filter 对代理程序进行安全检测,并在确认不会导致内核 panic 的前提下,将程序挂载到钩子 sk_filter 上。
/* Copied from net/core/filter.c */
int sk_attach_filter(struct sock_fprog *fprog, struct sock *sk)
{
struct sk_filter *fp, *old_fp;
unsigned int fsize = sizeof(struct sock_filter) * fprog->len;
int err;
fp = sock_kmalloc(sk, fsize+sizeof(*fp), GFP_KERNEL);
/* 从用户空间向内核空间拷贝代理程序 */
if (copy_from_user(fp->insns, fprog->filter, fsize)) {
sock_kfree_s(sk, fp, fsize+sizeof(*fp));
return -EFAULT;
}
atomic_set(&fp->refcnt, 1);
fp->len = fprog->len;
/* 在沙箱中对代理程序做安全检测 */
err = sk_chk_filter(fp->insns, fp->len);
if (err) {
sk_filter_uncharge(sk, fp);
return err;
}
rcu_read_lock_bh();
old_fp = rcu_dereference(sk->sk_filter);
/* 在 sk_filter 绑上经过检测的代理程序 */
rcu_assign_pointer(sk->sk_filter, fp);
rcu_read_unlock_bh();
if (old_fp)
sk_filter_delayed_uncharge(sk, old_fp);
return 0;
}
核心的安全检测函数是 sk_chk_filter 。BPF 的沙箱化处理,就是实现里一套精简指令集,提供有限的几十个指令以及几个寄存器,在内核模拟了一个小的处理器来执行代理程序。这里的安全检测,其核心就是检测是否存在非预期的指令,相关指令的非法配合,是否存在读取非法地址的情况以及程序是否以 BPF_RET 指令作为结束。
了解了代理程序的挂载,再来看看这个代理程序在网络协议栈中由谁触发,并如何完成令人惊艳的过滤工作。
/* Copied from net/packet/af_packet.c */
/* socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL)) 内核创建 packet 族套接字的核心流程 */
static int packet_create(struct net *net, struct socket *sock, int protocol)
{
/* some code omitted ... */
po = pkt_sk(sk);
sk->sk_family = PF_PACKET;
po->num = proto;
spin_lock_init(&po->bind_lock);
/* 配置协议相关钩子函数 */
po->prot_hook.func = packet_rcv;
/* 根据套接字的类型,有两类不同的钩子 */
if (sock->type == SOCK_PACKET)
po->prot_hook.func = packet_rcv_spkt;
if (proto) {
po->prot_hook.type = proto;
/* 将钩子函数直接与网络设备挂钩 */
dev_add_pack(&po->prot_hook);
sock_hold(sk);
po->running = 1;
}
}
/* 网络包(接收/发送)达到数据链路层,都将尝试调用预置的钩子函数 */
static int packet_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
sk = pt->af_packet_priv;
snaplen = skb->len;
/* 核心代理函数的触发逻辑 */
res = run_filter(skb, sk, snaplen);
if (!res)
goto drop_n_restore;
/* 根据代理函数执行结果,如果 res 不为零,则将这个 sk_buff 提交到之前创建的 packet 族的套接字等待队列 */
__skb_queue_tail(&sk->sk_receive_queue, skb);
}
static inline unsigned int run_filter(struct sk_buff *skb, struct sock *sk,
unsigned int res)
{
struct sk_filter *filter;
rcu_read_lock_bh();
filter = rcu_dereference(sk->sk_filter);
/* 存在代理函数,则尝试执行 */
if (filter != NULL)
res = sk_run_filter(skb, filter->insns, filter->len);
rcu_read_unlock_bh();
return res;
}
总的来说,创建的套接字 socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL)) 就相当于在数据链路层挂上了一个窃听程序,负责将命中的包全部提取到这个窃听套接字的接收队列中。至于内核空间到用户空间的数据提取工作,就像普通的套接字一样。直接使用 recv 系统调用读取套接字的接收队列也就完成了。
最后来看一下代理程序是如何沙箱化执行的。
/* Copied from net/core/filter.c */
/*
* 核心的实现就是模拟了一套简单的处理器,由累加器、索引寄存器、小块内存、PC 组成,
* 一般负责对一段数据的某些特定字节的校验工作
*/
unsigned int sk_run_filter(struct sk_buff *skb, struct sock_filter *filter, int flen)
{
struct sock_filter *fentry; /* We walk down these */
void *ptr;
u32 A = 0; /* Accumulator */
u32 X = 0; /* Index Register */
u32 mem[BPF_MEMWORDS]; /* Scratch Memory Store */
u32 tmp;
int k;
int pc;
/*
* Process array of filter instructions.
*/
for (pc = 0; pc < flen; pc++) {
fentry = &filter[pc];
switch (fentry->code) {
case BPF_ALU|BPF_ADD|BPF_X:
A += X;
continue;
case BPF_ALU|BPF_ADD|BPF_K:
A += fentry->k;
continue;
case BPF_ALU|BPF_SUB|BPF_X:
A -= X;
continue;
case BPF_ALU|BPF_SUB|BPF_K:
A -= fentry->k;
continue;
case BPF_ALU|BPF_MUL|BPF_X:
A *= X;
continue;
case BPF_ALU|BPF_MUL|BPF_K:
A *= fentry->k;
continue;
case BPF_ALU|BPF_DIV|BPF_X:
if (X == 0)
return 0;
A /= X;
continue;
case BPF_ALU|BPF_DIV|BPF_K:
A /= fentry->k;
continue;
case BPF_ALU|BPF_AND|BPF_X:
A &= X;
continue;
case BPF_ALU|BPF_AND|BPF_K:
A &= fentry->k;
continue;
case BPF_ALU|BPF_OR|BPF_X:
A |= X;
continue;
case BPF_ALU|BPF_OR|BPF_K:
A |= fentry->k;
continue;
case BPF_ALU|BPF_LSH|BPF_X:
A <<= X;
continue;
case BPF_ALU|BPF_LSH|BPF_K:
A <<= fentry->k;
continue;
case BPF_ALU|BPF_RSH|BPF_X:
A >>= X;
continue;
case BPF_ALU|BPF_RSH|BPF_K:
A >>= fentry->k;
continue;
case BPF_ALU|BPF_NEG:
A = -A;
continue;
case BPF_JMP|BPF_JA:
pc += fentry->k;
continue;
case BPF_JMP|BPF_JGT|BPF_K:
pc += (A > fentry->k) ? fentry->jt : fentry->jf;
continue;
case BPF_JMP|BPF_JGE|BPF_K:
pc += (A >= fentry->k) ? fentry->jt : fentry->jf;
continue;
case BPF_JMP|BPF_JEQ|BPF_K:
pc += (A == fentry->k) ? fentry->jt : fentry->jf;
continue;
case BPF_JMP|BPF_JSET|BPF_K:
pc += (A & fentry->k) ? fentry->jt : fentry->jf;
continue;
case BPF_JMP|BPF_JGT|BPF_X:
pc += (A > X) ? fentry->jt : fentry->jf;
continue;
case BPF_JMP|BPF_JGE|BPF_X:
pc += (A >= X) ? fentry->jt : fentry->jf;
continue;
case BPF_JMP|BPF_JEQ|BPF_X:
pc += (A == X) ? fentry->jt : fentry->jf;
continue;
case BPF_JMP|BPF_JSET|BPF_X:
pc += (A & X) ? fentry->jt : fentry->jf;
continue;
case BPF_LD|BPF_W|BPF_ABS:
k = fentry->k;
load_w:
ptr = load_pointer(skb, k, 4, &tmp);
if (ptr != NULL) {
A = ntohl(get_unaligned((__be32 *)ptr));
continue;
}
break;
case BPF_LD|BPF_H|BPF_ABS:
k = fentry->k;
load_h:
ptr = load_pointer(skb, k, 2, &tmp);
if (ptr != NULL) {
A = ntohs(get_unaligned((__be16 *)ptr));
continue;
}
break;
case BPF_LD|BPF_B|BPF_ABS:
k = fentry->k;
load_b:
ptr = load_pointer(skb, k, 1, &tmp);
if (ptr != NULL) {
A = *(u8 *)ptr;
continue;
}
break;
case BPF_LD|BPF_W|BPF_LEN:
A = skb->len;
continue;
case BPF_LDX|BPF_W|BPF_LEN:
X = skb->len;
continue;
case BPF_LD|BPF_W|BPF_IND:
k = X + fentry->k;
goto load_w;
case BPF_LD|BPF_H|BPF_IND:
k = X + fentry->k;
goto load_h;
case BPF_LD|BPF_B|BPF_IND:
k = X + fentry->k;
goto load_b;
case BPF_LDX|BPF_B|BPF_MSH:
ptr = load_pointer(skb, fentry->k, 1, &tmp);
if (ptr != NULL) {
X = (*(u8 *)ptr & 0xf) << 2;
continue;
}
return 0;
case BPF_LD|BPF_IMM:
A = fentry->k;
continue;
case BPF_LDX|BPF_IMM:
X = fentry->k;
continue;
case BPF_LD|BPF_MEM:
A = mem[fentry->k];
continue;
case BPF_LDX|BPF_MEM:
X = mem[fentry->k];
continue;
case BPF_MISC|BPF_TAX:
X = A;
continue;
case BPF_MISC|BPF_TXA:
A = X;
continue;
case BPF_RET|BPF_K:
return fentry->k;
case BPF_RET|BPF_A:
return A;
case BPF_ST:
mem[fentry->k] = A;
continue;
case BPF_STX:
mem[fentry->k] = X;
continue;
default:
WARN_ON(1);
return 0;
}
/*
* Handle ancillary data, which are impossible
* (or very difficult) to get parsing packet contents.
*/
switch (k-SKF_AD_OFF) {
case SKF_AD_PROTOCOL:
A = ntohs(skb->protocol);
continue;
case SKF_AD_PKTTYPE:
A = skb->pkt_type;
continue;
case SKF_AD_IFINDEX:
A = skb->dev->ifindex;
continue;
default:
return 0;
}
}
return 0;
}
BPF JIT 技术
沙箱执行虽然保证了内核的安全,无需担心用户随意定制的程序导致内核 panic 。但大量的网络包都需要经过这个沙箱的检测,这部分逻辑的效率就变得至关重要了。因此,在 Linux 3.x 版本之后,BPF 开始引入 JIT 技术来提高这部分代码的执行效率。
下列源代码均来自于 Linux 3.10.1 版本
以 BPF 指令 BPF_S_ALU_ADD_X 来讲,本质上 JIT 就是做完成编译的工作,将高级语言向低级语言做一个翻译工作。
/* Copied from arch/x86/net/bpf_jit_comp.c */
case BPF_S_ALU_ADD_X: /* A += X; */
seen |= SEEN_XREG;
EMIT2(0x01, 0xd8); /* add %ebx,%eax */
break;
在 x86 架构下,翻译作机器码的 add %ebx,%eax 就是 0x01d8 啦
void bpf_jit_compile(struct sk_filter *fp)
{
u8 temp[64];
u8 *prog;
unsigned int proglen, oldproglen = 0;
int ilen, i;
int t_offset, f_offset;
u8 t_op, f_op, seen = 0, pass;
u8 *image = NULL;
u8 *func;
int pc_ret0 = -1; /* bpf index of first RET #0 instruction (if any) */
unsigned int cleanup_addr; /* epilogue code offset */
unsigned int *addrs;
const struct sock_filter *filter = fp->insns;
int flen = fp->len;
if (!bpf_jit_enable)
return;
addrs = kmalloc(flen * sizeof(*addrs), GFP_KERNEL);
if (addrs == NULL)
return;
/* Before first pass, make a rough estimation of addrs[]
* each bpf instruction is translated to less than 64 bytes
*/
for (proglen = 0, i = 0; i < flen; i++) {
proglen += 64;
addrs[i] = proglen;
}
cleanup_addr = proglen; /* epilogue address */
for (pass = 0; pass < 10; pass++) {
u8 seen_or_pass0 = (pass == 0) ? (SEEN_XREG | SEEN_DATAREF | SEEN_MEM) : seen;
/* no prologue/epilogue for trivial filters (RET something) */
proglen = 0;
prog = temp;
/* some code omitted ... */
/*
* JIT 全部基于 prog 指针实施,temp 和 prog 就分别作为 JIT 机器码的头尾指针。
* 所有翻译成的机器码全部存储在 temp 指向的内存区域
*/
ilen = prog - temp;
if (image) {
if (unlikely(proglen + ilen > oldproglen)) {
pr_err("bpb_jit_compile fatal error\n");
kfree(addrs);
module_free(NULL, image);
return;
}
/* 最终 JIT 之后的机器码会全部拷贝到 image 指向的内存区域 */
memcpy(image + proglen, temp, ilen);
}
proglen += ilen;
addrs[i] = proglen;
prog = temp;
if (image) {
if (proglen != oldproglen)
pr_err("bpb_jit_compile proglen=%u != oldproglen=%u\n", proglen, oldproglen);
break;
}
if (proglen == oldproglen) {
image = module_alloc(max_t(unsigned int,
proglen,
sizeof(struct work_struct)));
if (!image)
goto out;
}
oldproglen = proglen;
}
if (image) {
bpf_flush_icache(image, image + proglen);
/* image 指向的机器码就直接替代了非 JIT 下的 sk_run_filter 函数 */
fp->bpf_func = (void *)image;
}
out:
kfree(addrs);
return;
}
JIT 编译完成后的机器码,完全可以类比 C 语言在编译后的 ELF 文件中的机器码。是可以交由 CPU 直接执行的。而由 CPU 直接执行的效率,一般都是高于基于 CPU 模拟的一套处理器的。