最近频繁发布应用,Tomcat 的启动效率竟然莫名其妙地出现了断崖式下降。正常 30 秒左右启动的应用,硬生生花了将近 7 分钟。通过检索日志发现了一些有意思的内容。
16-Oct-2019 14:23:31.999 WARNING [localhost-startStop-1] org.apache.catalina.util.SessionIdGeneratorBase.createSecureRandom Creation of SecureRandom instance for session ID generation using [SHA1PRNG] took [386,690] milliseconds.
...
16-Oct-2019 14:23:33.111 INFO [main] org.apache.catalina.startup.Catalina.start Server startup in 410675 ms
创建 SecureRandom 竟然花了 6 分多钟,占了整个启动时间的 94% 。
SecureRandom
SessionIdGeneratorBase 创建 SecureRandom 的核心代码可以归结为:
import java.security.NoSuchAlgorithmException;
import java.security.SecureRandom;
/**
* @author ffutop
* @since 2019/10/17
*/
public class Random {
public void run() {
SecureRandom result = null;
long t1 = System.currentTimeMillis();
try {
result = SecureRandom.getInstance("SHA1PRNG");
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
// Force seeding to take place
result.nextInt();
long t2 = System.currentTimeMillis();
System.out.println(Long.valueOf(t2 - t1) + " ms");
for (int i=0;i<10000;i++)
System.out.println(result.nextInt());
long t3 = System.currentTimeMillis();
System.out.println(Long.valueOf(t3 - t2) + " ms");
}
public static void main(String[] args) {
System.out.println("start run()");
new Random().run();
System.out.println("stop run()");
}
}
执行结果直接表明了首次 result.nextInt() 花费的时间绝大于之后 10000 次 nextInt() 的时间。
$ javac Random.java
$ java Random
start run()
210635 ms
81 ms
stop run()
利用 jstack 与 strace 发现,main 线程应该是阻塞在生成随机数种子的过程。监控系统调用的结果是读操作阻塞在读取 /dev/random 数据。
// jstack result (part)
"main" #1 prio=5 os_prio=0 tid=0x00007f3b94010800 nid=0xda0 runnable [0x00007f3b9ca57000]
java.lang.Thread.State: RUNNABLE
at java.io.FileInputStream.readBytes([email protected]/Native Method)
at java.io.FileInputStream.read([email protected]/FileInputStream.java:280)
at java.io.FilterInputStream.read([email protected]/FilterInputStream.java:133)
at sun.security.provider.SeedGenerator$URLSeedGenerator.getSeedBytes([email protected]/SeedGenerator.java:541)
at sun.security.provider.SeedGenerator.generateSeed([email protected]/SeedGenerator.java:144)
at sun.security.provider.SecureRandom$SeederHolder.<clinit>([email protected]/SecureRandom.java:204)
at sun.security.provider.SecureRandom.engineNextBytes([email protected]/SecureRandom.java:222)
- locked <0x00000000e0d02e20> (a sun.security.provider.SecureRandom)
at java.security.SecureRandom.nextBytes([email protected]/SecureRandom.java:741)
at java.security.SecureRandom.next([email protected]/SecureRandom.java:798)
at java.util.Random.nextInt([email protected]/Random.java:329)
at Ran.run(Ran.java:20)
at Ran.main(Ran.java:32)
// strace result (part)
[pid 3645] openat(AT_FDCWD, "/dev/random", O_RDONLY) = 4
...
[pid 3645] read(4, <unfinished ...>
Linux 随机数生成器工作原理
计算机作为高度可预测的设备,很难真正意义上生成随机数,但这可以通过伪随机数算法来解决。不过伪随机数有相当致命的缺陷——对攻击者而言,可以通过各种手段猜测伪随机数序列。这对于一些应用而言,是完全无法接受的。
为了解决这些问题,随机数生成器通过收集攻击者难以观测到的计算机“环境噪音”,并基于这些因素来确保生成的随机数的不可预测性。这些“噪音”包括键盘、鼠标、某些中断的中断计时以及其它拥有不确定性和难以被观测的因素。这些因素被利用类似CRC校验机制的方式加入到“熵池”中。虽然CRC的方案从密码学的角度看并不足够安全,但重在难以预测,并且速度足够快。这些收集到的“环境噪音”将被添加到熵池中,并通过熵值计数器来维护基于现状能够生成多少位随机数。
当需要随机数时,从熵池中提取随机因子,经过SHA-1算法加工后就成了随机数。当熵值计数器低于预设的阈值(确保有足够的因子能够生成安全的随机数)时,此时随机数生成器将陷入阻塞。
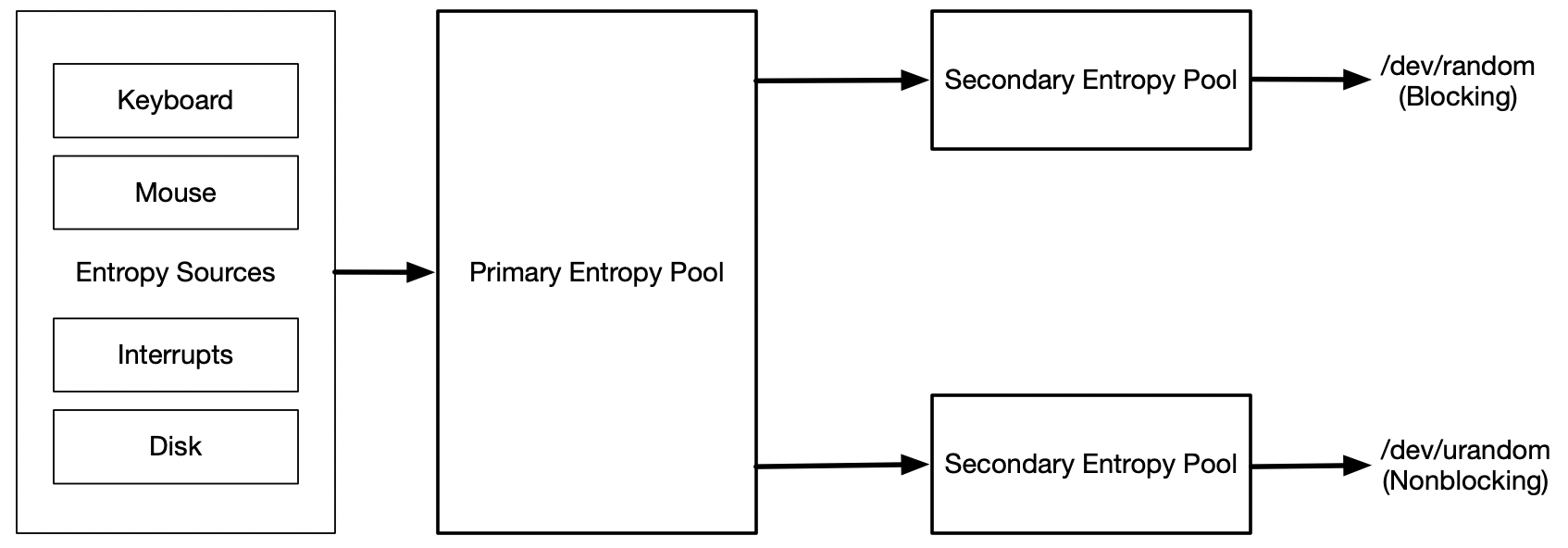
/dev/random 和 /dev/urandom 作为 Linux 系统内核向用户层提供的两个随机数生成接口,工作形式分别是阻塞式与非阻塞式。当熵池收集的噪音不足时,/dev/random 的策略是让当前任务主动陷入 Sleeping 状态。而 /dev/urandom 则通过牺牲一定程度的随机性来保证随机数的生成效率。
从源代码来看,random_read 和 urandom_read 调用了相同的函数 extract_entropy_user 来从熵池中提取随机数。不过 random 通过循环从 blocking_pool 分多次提取,每次最多提取 SEC_XFER_SIZE (=512) 字节,而 urandom 则一次性从 nonblocking_pool 全量提取随机数。数据的流向见上图所示。
static ssize_t
random_read(struct file *file, char __user *buf, size_t nbytes, loff_t *ppos)
{
ssize_t n, retval = 0, count = 0;
if (nbytes == 0)
return 0;
while (nbytes > 0) {
n = nbytes;
/* 需求的字节数大于安全提取的阈值,则分多次提取。保证每次不超限 */
if (n > SEC_XFER_SIZE)
n = SEC_XFER_SIZE;
DEBUG_ENT("reading %zu bits\n", n*8);
/* 提取熵,并拷贝到用户空间 */
n = extract_entropy_user(&blocking_pool, buf, n);
if (n < 0) {
retval = n;
break;
}
DEBUG_ENT("read got %zd bits (%zd still needed)\n",
n*8, (nbytes-n)*8);
if (n == 0) {
/* 不支持非阻塞的文件标识 */
if (file->f_flags & O_NONBLOCK) {
retval = -EAGAIN;
break;
}
DEBUG_ENT("sleeping?\n");
/* 主动 Sleeping,等待事件(熵池被填充达到一定的阈值)*/
wait_event_interruptible(random_read_wait,
input_pool.entropy_count >=
random_read_wakeup_thresh);
DEBUG_ENT("awake\n");
if (signal_pending(current)) {
retval = -ERESTARTSYS;
break;
}
continue;
}
count += n;
buf += n;
nbytes -= n;
break; /* This break makes the device work */
/* like a named pipe */
}
return (count ? count : retval);
}
static ssize_t
urandom_read(struct file *file, char __user *buf, size_t nbytes, loff_t *ppos)
{
/* 提取熵,并拷贝到用户空间 */
return extract_entropy_user(&nonblocking_pool, buf, nbytes);
}
从全流程来说,random 和 urandom 几乎都是一样的,最重要的区别在于 random 通过比较熵值计时器与预设阈值,来决定是否需要等待熵池收集到足够的随机因子后再进行随机数生成工作。而 urandom 的工作形式就是不设定阈值,非阻塞式直接生成随机数。从使用的角度来说,如果保持熵池充足,并且每次要求的随机数小于 512 字节,那么 random 和 urandom 的执行将是一致的(当然,这个一致是指执行的逻辑一致,不代表结果一致)。大雾,熵池真的充足的话,又何必考虑 urandom 呢?
解决方案
Tomcat Wiki 从两个角度提供了解决方案:
- 放弃使用
/dev/random,改用非阻塞式的/dev/urandom。添加启动参数-Djava.security.egd=file:/dev/./urandom - 增加熵池的来源,提供熵的产量。通过购买外设
EntropyKey来解决;或者使用软件来模拟一些环境噪音,比如 rngd 。