虽然我们在日常沟通中把 Goroutine 和线程、协程之类的执行流概念混杂着沟通,但 Go 语言一直坚持 “Goroutine”。 宣称这一名词的产生是由于线程、协程、进程等无法准确表达其概念。本篇将就这一声明进行探究,Goroutine 与线程、协程究竟有何不同。
Goroutine 设计
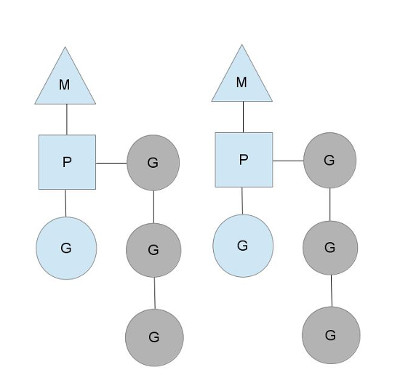
M: 代表操作系统所认知的线程,比如标准的 POSIX 线程P: 代表可用于执行 Go 代码的处理器 (Processes)G: 代表并发的执行单元 (Goroutine)
Copied From The Go scheduler
M 代表 Go 程序在操作系统的认知中创建了 m 个线程。P 必须与 M 绑定才能得到真正的物理计算资源来执行逻辑。
再向上一层,G (Goroutine) 与 M 无直接关联(当然,早期的 Go 语言模型下,没有 P 这一层抽象)。与内核类比,P 与 G 也构成了一个简单的核与线程的关系。G 通过被调度到 P 上,获得计算资源,否则就被添加到 P 相关的等待队列。当然,P 与 G 没有直接的绑定关系,当 $P_1$ 空闲时,$P_2$ 等待队列上的 G 可以被调度到 $P_1$ 上继续执行。
Go 进程的启动
在 Go 语言中,每一个并发的执行单元都被称为一个 Goroutine ,即使是 Go 程序的主函数(func main()) 也不例外。启动一个 Go 进程,其实可以类比成内核或者虚拟机的启动。那么,顺着这套思路,先来看看 main Goroutine 是如何启动的。
Go 语言最终会被编译成适配平台的机器码,不走虚拟机那一套。在 Linux 平台上,编译后的文件格式是 ELF 。熟悉的朋友可以很快地通过 GDB 等工具找到真正的入口函数(Entry Point)。第一个重要的入口函数是 runtime·rt0_go 。
// Source: src/runtime/asm_amd64.s
TEXT runtime·rt0_go(SB),NOSPLIT,$0
// 程序启动时,被认为是单线程任务。
// 将当前线程的栈和资源绑定到 g0
// 将当前线程作为 m0 记录
// Some Code Omitted ...
// TLS: Thread Local Storage
get_tls(BX)
LEAQ runtime·g0(SB), CX
MOVQ CX, g(BX)
LEAQ runtime·m0(SB), AX
// m0 和 g0 相互绑定
MOVQ CX, m_g0(AX)
MOVQ AX, g_m(CX)
// 解析命令行参数
CALL runtime·args(SB)
// 初始化 CPU 核数
CALL runtime·osinit(SB)
// 内存分配器、栈、GC、P 等初始化
CALL runtime·schedinit(SB)
// create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
PUSHQ $0 // arg size
CALL runtime·newproc(SB)
POPQ AX
POPQ AX
// start this M
CALL runtime·mstart(SB)
CALL runtime·abort(SB) // mstart should never return
runtime·schedinit 负责对调度系统做初始化。最重要的就是将所有的 P 都提前创建好,置于全局队列等待使用。
// Source: src/runtime/proc.go
func schedinit() {
// Some Code Omitted ...
stackinit()
mallocinit()
// 初始化 M
mcommoninit(_g_.m)
gcinit()
sched.lastpoll = uint64(nanotime())
// P 的数量,默认为系统可用的 CPU 核数
procs := ncpu
// 或者被用户强制指定为 GOMAXPROCS
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
// 调整 P 个数,这里是新分配 procs 个新的 P
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
}
runtime.newproc 负责创建新的 Goroutine ,可以类比内核的 fork 。新的 Goroutine 创建完成后并不直接被执行,而是添加到 P 或全局的等待队列(取决于 P 本地队列是否满了),由调度器来决定何时给新的 Goroutine 分配计算资源。这里有一个特殊的函数 systemstack ,所有调度相关的函数都需要通过它来进行调用。具体来说,每个 M 都有一个特殊的 Goroutine (g0) ,只负责调度相关的工作,不负责具体的用户逻辑工作。systemstack 做的就是将当前 Goroutine 的上下文 SP, PC, g, CTXT 等暂存,并将当前 Goroutine 所在的线程 M 的上下文切换为 g0 的上下文,完成函数 func 的执行后,在恢复原 Goroutine 的上下文。
另一点不得不提一下,Go 编程中使用 go 作为开启一个新 Goroutine 的关键词。而在编译后,go 关键词也是会被翻译成 newproc 。
// Source: src/runtime/proc.go
func newproc(siz int32, fn *funcval) {
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
gp := getg()
pc := getcallerpc()
systemstack(func() {
newproc1(fn, (*uint8)(argp), siz, gp, pc)
})
}
func newproc1(fn *funcval, argp *uint8, narg int32, callergp *g, callerpc uintptr) {
// 拿到当前的 Goroutine
_g_ := getg()
// 找到 Goroutine 所绑定的 P
_p_ := _g_.m.p.ptr()
// 从 P.gfree 中获取一个 G 或者 sched.gFree 中获取
// 这样可以复用之前已经被回收的 G
newg := gfget(_p_)
if newg == nil {
// 没获取到,就只能新建一个 G
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
// 把新的 G 添加到 P 的本地等待队列中
// 如果 P 的本地队列满了,就添加到全局等待队列中
runqput(_p_, newg, true)
// 如果有空闲的 P ,且有 M 陷入自旋等待,就进行唤醒
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 && mainStarted {
wakep()
}
}
最后一步,回到 runtime·rt0_go ,执行 runtime·mstart 首次使用调度器进行调度,并将一个执行单元调度到 M 上进行执行。
Goroutine 调度
首先需要意识到的是:在进行首次调度之前,M 作为操作系统线程的抽象,从 Go 进程启动那刻起,就已经在工作了。只是在启动过程中给这个线程声明了个实体,并宣称这是 M 。
调度一般分协作式调度和抢占式调度。协作式调度由执行单元主动放弃计算资源;抢占式一般由一个后台任务负责对所有执行单元进行把控,强制取回交给一个执行单元的计算资源并交给另一个。Go 从 1.4 版本开始,加入了抢占式调度。其调度多发生在 sysmon 定期触发的调度、Goroutine 执行完结、Go 进程初始化调度 runtime·main 函数等。调度以 schedule 函数为核心。
// Source: src/runtime/proc.go
func schedule() {
_g_ := getg()
top:
var gp *g
var inheritTime bool
if gp == nil && gcBlackenEnabled != 0 {
gp = gcController.findRunnableGCWorker(_g_.m.p.ptr())
tryWakeP = tryWakeP || gp != nil
}
if gp == nil {
// Goroutine 等待队列分为 M 本地队列和全局队列
// 需要定期从全局队列中把 Goroutine 拉到 M 本地队列,保证这些 G 也被执行
// 这里控制的频率是每 61 次取一次
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil {
// 从 M 的本地队列取 Goroutine
gp, inheritTime = runqget(_g_.m.p.ptr())
if gp != nil && _g_.m.spinning {
throw("schedule: spinning with local work")
}
}
if gp == nil {
// 1. 尝试从本地队列取
// 2. 尝试从全局 Goroutine 就绪队列中获取
// 3. 从 epoll 里获取
// 4. 尝试从其他 P 的 Goroutine 队列中偷取一些
// 5. 阻塞,直到能取到为止
gp, inheritTime = findrunnable()
}
// ... Some Code Omitted
// 执行获取到的 Goroutine
execute(gp, inheritTime)
}
execute 会对即将执行的 Goroutine 的状态重置,从 Runnable 到 Running 。再就是将 Goroutine 维持的上下文恢复,并继续这个 Goroutine 上一次被中断时的逻辑。
看过调度的逻辑,那么调度又如何被触发呢?
- 抢占式调度必然有一个中枢负责对计算资源的分配,
sysmon就在 Go 进程中承担这样的工作。
sysmon 类似操作系统的守护进程,或者是内核线程。无限循环,定期处理全局工作。就调度而已,它会对长时间占用计算资源的 Goroutine 进行标记。是的,只进行标记。调度的触发会发生在栈扩张时期,核心逻辑实现上会让 Goroutine 检查抢占标记,让出 M 并调用 schedule 。所以从实现上看,其实还是协作式的思路,只不过由一个抢占式的中枢进行辅助提示。
// Source: src/runtime/proc.go
func sysmon() {
idle := 0 // how many cycles in succession we had not wokeup somebody
delay := uint32(0)
for {
// delay 控制 for 循环间隔,避免无限死循环导致的 CPU 100% 使用率
// 前 50 次每次 sleep 20 微秒,超过 50 次则每次翻 2 倍,直到最大 10 毫秒
if idle == 0 { // start with 20us sleep...
delay = 20
} else if idle > 50 { // start doubling the sleep after 1ms...
delay *= 2
}
if delay > 10*1000 { // up to 10ms
delay = 10 * 1000
}
usleep(delay)
if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now {
atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now))
list := netpoll(false) // non-blocking - returns list of goroutines
if !list.empty() {
incidlelocked(-1)
// 把 Epoll ready 的 Goroutine 列表加到全局 runq 队列
injectglist(&list)
incidlelocked(1)
}
}
// 回收陷入系统调用的 Goroutine
// and 标记占用计算资源时间过长的 Goroutine
if retake(now) != 0 {
idle = 0
} else {
idle++
}
}
}
- 用户级 Go 进程无法掌控内核级的系统调用,另一个调度发生在这个时期。
// Source: src/syscall/asm_linux_amd64.s
TEXT ·Syscall(SB),NOSPLIT,$0-56
CALL runtime·entersyscall(SB)
// Some Code Omitted ...
MOVQ trap+0(FP), AX // syscall entry
SYSCALL
// Some Code Omitted ...
CALL runtime·exitsyscall(SB)
RET
// Source: src/runtime/proc.go
func entersyscall() {
reentersyscall(getcallerpc(), getcallersp())
}
func reentersyscall(pc, sp uintptr) {
_g_ := getg()
_g_.stackguard0 = stackPreempt
_g_.throwsplit = true
_g_.syscallsp = sp
_g_.syscallpc = pc
casgstatus(_g_, _Grunning, _Gsyscall)
}
- 系统调用会阻塞 Goroutine,另一个阻塞 Goroutine 的就是 Channel 了。这同样会触发调度,避免等待 Go 程通信导致的空转
Goroutine 通信 – Channel
Channel 的实现走的是事件驱动的设计,粗略地看可以类比内核网络栈的 recv, send 。不过本篇重在 Goroutine 及其调度机制,暂时忽略 Channel 实现吧。
chan<- 和 <-chan 分别被编译做函数族 chansend 和 chanrecv 。
// Source: src/runtime/chan.go
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
if c == nil {
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// Block on the channel. Some receiver will complete our operation for us.
goparkunlock(&c.lock, waitReasonChanSend, traceEvGoBlockSend, 3)
// Some Code Omitted ...
}
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
if c == nil {
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// no sender available: block on this channel.
goparkunlock(&c.lock, waitReasonChanReceive, traceEvGoBlockRecv, 3)
// Some Code Omitted ...
}
当 Channel 陷入阻塞,不可直接读写时(如读取方等待 channel 被写入数据;channel 数据换成满了,等待读取方读取后再写入),调用 chansend 或 chanrecv 的 Goroutine 将触发 gopark ,当前 Goroutine 的状态被标记为 _Gwaiting ,再调用调度器将计算资源交给其他 Goroutine。
总结
回到最初的问题,Goroutine 与线程、协程有何区别呢?
从调度方式看,典型的线程是抢占式调度;协程是协作式调度。而 Goroutine 作为用户级执行控制流的实现,兼具了线程和协程的特征。Go 的 sysmon 实现了抢占式调度,会对 Goroutine 进行标记,但又不会直接参与调度 Goroutine ,反而是 Goroutine 自发地根据被标记的状态触发调度器。
从概念上,协程提供的仅仅是并发的机制,一般不会提到并行。而 Goroutine 可以并行地与其它 Goroutine 运行在同一地址空间的进程中。当然,对于线程来说,并行也是其使用中的一大特征(前提是基于 SMP)。
最后,自然是从规范上来讲。究竟又是由谁明确地定义了线程、协程?事实上即使是 POSIX 规范下的 Thread ,Linux 也没有完全实现其定义所有接口。而对于 Go 来说,显然它压根就没有实现 Pthread ;至于协程,似乎还停留在概念,各门语言各有实现,而没有统一的规范。
既然 Goroutine 无法 100% 的向线程、协程的概念靠拢,定义一个新概念也无不可。
参考资料
[1]. Dmitry Vyukov. May 2, 2012. “Scalable Go Scheduler Design Doc” https://golang.org/s/go11sched
[2]. May 23rd, 2019. “详尽干货!从源码角度看 Golang 的调度” https://mp.weixin.qq.com/s/laxAshXPQvzRhFg3RtZJOw