分布式系统与共识
分布式系统是一组透过网络相互连接通信与传递信息的计算机,协同来完成一件任务的系统。任务可能是大规模计算,可能是冗余存储。按此分类,又有分布式计算系统和分布式存储系统。
典型的分布式计算系统/框架有 MapReduce、Spark;分布式存储系统有 GFS 等。虽然有此划分,但分布式计算几乎必然地涉及到存储的需求。存储为计算提供支持,计算促进存储的发展。

计算是无状态的,存储是有状态的。在分布式的存储下,为了让计算机各自维护的状态协商达成一致,就必然地需要共识算法的支持。Wait a minute. 计算机间的协商需要共识算法?
计算机间的协作可以划分为中心化与去中心化两大类。中心化的方案自然是有一个权威的 Master 来协调所有的计算机的任务,但前提是这个 Master 必须可靠,即依赖一个单点就必须要对它的可用性进行担保;去中心化的方案,计算机间都是平等的,如何就一个问题达成共识,就是面对的核心问题。
共识与一致性
共识(Consensus):机器之间就一个值/命令等达成共同的认识,一般是面向输入,处理并维护这个值(状态)
一致性(Consistency):一致性表述为机器对外提供服务时的表现。向机器 A 或机器 B 读取同一数据,两者的返回值是相同的。当然,也有不同的弱化版本,允许一些特定条件下的不一致
在 2014 年之前,Paxos [1] 几乎是解决共识问题的唯一选择。但难懂是一个致命的问题,并且难以工程化也是重大的缺陷。Raft 的出现无疑是一道曙光,熟读,实践,豁然开朗。
Raft
零零总总,花了差不多3周半的时间,基于 MIT 6.824 Lab 2 [4] 造了个勉强能够转得起来的轮子。期间反复琢磨的,甚至两度推到重写的,源于单个 Server 的并发问题。最终总算是依靠事件驱动模式解决了。

Raft 将解决共识问题,划分成三个子问题,以领导选举(Leader Election)为基础,日志复制(Log Replication)作为需要达成共识的数据的载体,围绕安全形成了完整的解决方案。
 Copy From Raft[3] Figure. 2
Copy From Raft[3] Figure. 2
领导选举
先抛开所有的前置问题。一个人做决策比一群人做决策要容易得多。领导选举,要做的就是将一群决策者变成一个决策者,其它的人只需要跟从即可。Raft 解决的第一个子问题,就是把一群变成了一个。通过领导选举,保证同一个任期只会有一个权威的声音。同时,当领导出现故障时,重新进行选举,产生新的领导。
先解释一下“任期”,在分布式系统里,由于网络及对其它节点的不确定性,消息的传递可能丢失、延迟、重复。Raft 使用任期充当逻辑时钟,任期号大的节点 A 收到任期号小的节点 B 的请求,响应时需要告知自己的任期号,并要求 B 及时更新。任期号小的节点 C 收到任期号大的节点 D 的请求,则 C 需要主动更新自己的任期号。
在 Raft 中,只有三种状态:
- 跟随者(Follower)
- 候选人(Candidate)
- 领导者(Leader)
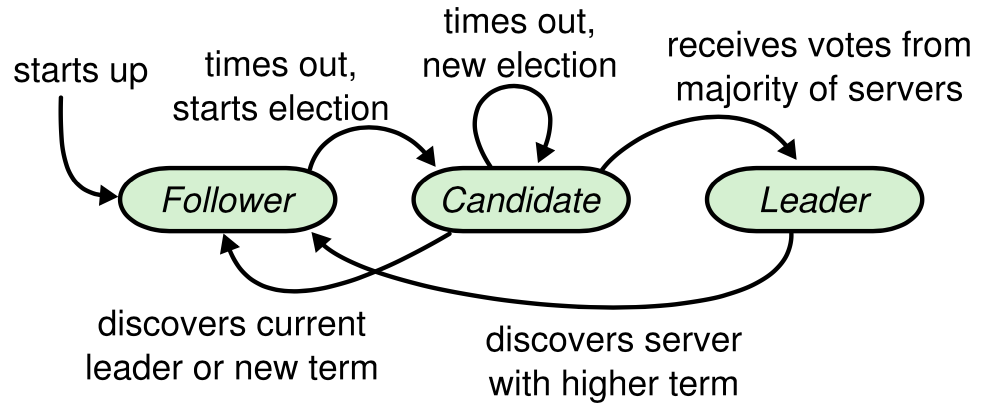 Copy From Raft[3] Figure. 4
Copy From Raft[3] Figure. 4
由于分布式下的不可靠,丢包、延迟、单点故障等都可能出现,领导选举能够保证的,是:
同一个任期号最多只有一个领导者(可能没有),因为跟随者总是响应最新的任期号,候选者需要得到大多数(指大于1/2的节点,包括自己,下同)的投票
由随机数支持的选举超时时间,让多个候选人同时存在时,冲突总能够有化解的余地
日志复制
常态下的日志复制最简单不过,领导者接受新的日志,并保证日志永远只能依次附加在最后,而不能删除之前的任何日志;跟随者通过接受领导者发送的 AppendEntries RPC 来得到新的日志,跟随者需要保持日志与领导者完全一致,有不一致的,需要删除老的日志,并依次附加新的日志。
如此这般,就不得不怀疑日志丢失的问题了?不过,没有大问题。
Raft 的日志附加也是分为两阶段的。第一阶段,只有领导者能够接收日志,并通过 AppendEntries RPC 向跟随者同步日志;第二阶段,领导者只有收到大多数跟随者的成功响应,才会将这条日志的状态改为“已提交”,并在随后请其它节点也提交这条日志。有几个问题:
- 如果有多个节点在收到日志时,都是领导者(任期号不同)。任期号小的领导者一定是失败的。因为任期号大的领导者的出现,必然将大于1/2的节点的任期号更新成较大的。
- 没有领导者,或者领导者收到后,未成功提交就宕机了。那么基本上是客户端重新发送请求,或者领导者迅速恢复。不过未提交的日志,无需保证其不丢失。
- 如果是“已提交”的日志,如何保证其在新的领导者的 AppendEntries RPC 下一定不会被覆盖掉呢?领导选举有一额外的策略要求,候选者的最后一条日志至少需要和跟随者一样新,跟随者才会投票给这个候选者。日志“已提交”,至少大于1/2节点都有这条日志,而候选者必须得到大于1/2的投票,才能变成领导者。
安全
对安全就不多加描述,它分散在领导选举和日志复制两个子问题中,对整个 Raft 做担保。
| 特性 | 解释 |
|---|---|
| 选举安全特性 | 对于一个给定的任期号,最多只会有一个领导人被选举出来 |
| 领导人只附加原则 | 领导人绝对不会删除或者覆盖自己的日志,只会增加 |
| 日志匹配原则 | 如果两个日志在相同的索引位置的日志条目的任期号相同,那么我们就认为这个日志从头到这个索引位置之间全部完全相同 |
| 领导人完全特性 | 如果某个日志条目在某个任期号中已经被提交,那么这个条目必然出现在更大任期号的所有领导人中 |
| 状态机安全特性 | 如果一个领导人已经将给定的索引值位置的日志条目应用到状态机中,那么其他任何的服务器在这个索引位置不会应用一个不同的日志 |
单节点的并发问题
两次推翻代码,都是因为在单节点的并发处理上存在很大问题。虽然多个 Raft 节点之间的共识问题通过算法能够很好地处理,而且理解上也不存在障碍。不过单节点的并发导致了相当多的问题。包括
- 低任期领导者收到高任期领导者的心跳,需要自行降级成跟随者;
- 领导者需要广播 AppendEntries RPC;
- 跟随者既要维护选举超时心跳等待自动成为候选人,也要等待领导者的心跳
- 等等…
对上述问题的处理都不是一个原子事件,那么并发就是不得不考虑的问题。
不过,既然网络是不可靠的,问题也就完全可以通过事件驱动的方案,用串行的思路来解。同时有多个请求到达,那就都打包成事件等待处理即可。认识上可以等同于网络导致的延迟。毕竟 Raft 已经充分考虑了这个问题了。
- 跟随者监听 AppendEntries 和 RequestVote 事件以及选举超时事件
func (rf *Raft) followerLoop() {
rf.votedFor = notVoted
for rf.State() == StateFollower {
select {
case ev := <-rf.c:
var err error
switch req := ev.req.(type) {
case *AppendEntriesArgs:
ev.resp = rf.processAppendEntries(req)
case *RequestVoteArgs:
ev.resp = rf.processRequestVote(req)
}
ev.c <- err
case <-time.After(randElectionTick()):
rf.setState(StateCandidate)
}
}
}
- 候选人每个候选周期发送 RequestVote,并等待其它的 AppendEntries、RequestVote 和选举响应、选举超时事件
func (rf *Raft) candidateLoop() {
newTerm := true
var timeoutChan <-chan time.Time
var replyChan chan *RequestVoteReply
for rf.State() == StateCandidate {
if newTerm {
newTerm = false
rf.incTerm()
rf.voteCount = 1
rf.votedFor = rf.me
replyChan = make(chan *RequestVoteReply, rf.nPeers)
for i := 0; i < rf.nPeers; i++ {
if i == rf.me {
continue
}
entry := rf.log.LastEntry()
args := &RequestVoteArgs{
Term: rf.Term(),
CandidateId: rf.me,
LastLogIndex: entry.Index,
LastLogTerm: entry.Term,
}
go rf.sendRequestVote(i, args, replyChan)
}
timeoutChan = time.After(randElectionTick())
}
select {
case reply := <-replyChan:
rf.commonRule(reply.Term)
if rf.State() == StateCandidate && reply.VoteGranted {
rf.voteCount++
DPrintf("raft %v get new vote, total: %v", rf.me, rf.voteCount)
if rf.voteCount > (rf.nPeers >> 1) {
rf.setState(StateLeader)
}
}
case ev := <-rf.c:
var err error
switch req := ev.req.(type) {
case *AppendEntriesArgs:
ev.resp = rf.processAppendEntries(req)
case *RequestVoteArgs:
ev.resp = rf.processRequestVote(req)
default:
err = UnknownEventErr
}
ev.c <- err
case <-timeoutChan:
newTerm = true
}
}
}
- 领导者需要定期发送 AppendEntries,并等待其它 RequestVote 和 AppendEntries 事件
func (rf *Raft) leaderLoop() {
for i := 0; i < rf.nPeers; i++ {
rf.nextIndex[i] = rf.log.NextIndex()
rf.matchIndex[i] = 0
}
var tickChan <-chan time.Time
newHeartbeat := true
var replyChan chan *AppendEntriesReply
for rf.State() == StateLeader {
if newHeartbeat {
rf.updateCommitIndex()
replyChan = make(chan *AppendEntriesReply)
for i := 0; i < rf.nPeers; i++ {
if i == rf.me {
continue
}
entries := rf.log.Entries(rf.nextIndex[i] - 1)
prevLogEntry := entries[0]
args := &AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: prevLogEntry.Index,
PrevLogTerm: prevLogEntry.Term,
Entries: entries[1:],
LeaderCommit: rf.log.commitIndex,
}
go rf.sendAppendEntries(i, args, replyChan)
}
tickChan = time.After(fixedHeartbeatTick())
newHeartbeat = false
}
select {
case reply := <-replyChan:
rf.commonRule(reply.Term)
case ev := <-rf.c:
var err error
switch req := ev.req.(type) {
case *AppendEntriesArgs:
ev.resp = rf.processAppendEntries(req)
case *RequestVoteArgs:
ev.resp = rf.processRequestVote(req)
default:
err = UnknownEventErr
}
ev.c <- err
case <-tickChan:
newHeartbeat = true
}
}
}
参考资料
[1]. _Wikipedia: Paxos _https://en.wikipedia.org/wiki/Paxos_(computer_science)
[2]. The Raft Consensus Algorithm https://raft.github.io/
[3]. In Search of an Understandable Consensus Algorithm(Extended Version) https://raft.github.io/raft.pdf
[4]. MIT 6.824 https://pdos.csail.mit.edu/6.824/schedule.html