我们生产环境上所有的应用都是通过域名来访问 MySQL、Redis 等基础服务。按说域名相较于 IP,凭空多了个 DNS 解析动作,是一个劣化的方案。但好处在于,一旦需要切换基础服务,将带来巨大的利好。可是,任何忽视DNS Record TTL的切换方案,都将伴随着巨大的风险。甚至,成为否定该利好的佐证。
权威 DNS 服务器工作原理
在 Linux 机器上,我们总能找到 /etc/hosts 文件,可以通过修改它来强制指定一些 DNS 记录。而域名系统(Domain Name System, DNS) 的雏形,也就是这样一份由 NIC 集中维护的 HOSTS.TXT 文件。 HOSTS 负责维护域名(用户可方便记忆的字符串)到 IP 地址的映射。不过,集中式服务带来的巨大访问量,以及滞后的记录维护工作,最终促使了 DNS 的诞生。
新生的 DNS 带来了全新的域名-IP映射维护方案。树形结构的名称空间将权威服务器的工作进一步细分。13台根服务器不提供所有域名的解析服务,而只是提供顶级域名(顶级名称空间,Like COM. CN. etc.)的解析。进一步的,顶级域名com的权威服务器负责提供 xxx.com 的二级域名解析工作。以此类推…
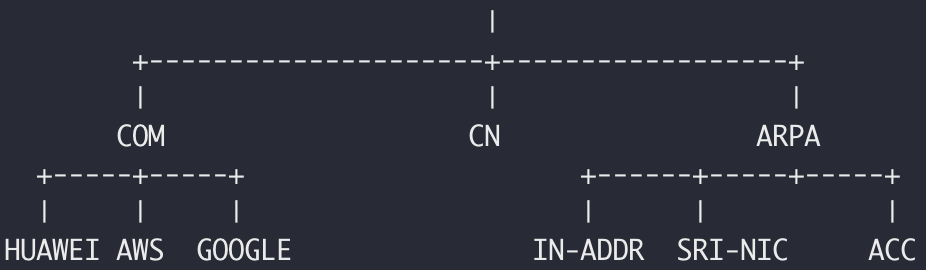
树形结构的域名
那么,一个具体的域名,是如何解析得到 IP 的呢?首先,你必须知道根域名服务器的 IP。named.root 文件是整个流程的开端。鸡和蛋的问题在这里的结论是先有鸡,才有蛋。以 www.ffutop.com 为例,模拟一下整个流程。
向根服务器A(IP: 198.41.0.4)询问,响应结果为——为顶级域名 com. 提供解析服务的权威服务器为
[a-m].gtld-servers.net.并提供了每个权威服务器域名的 IP 地址(毕竟再对[a-m].gtld-servers.net做域名解析带来的递归问题可是没完没了)。下一步
dig 192.5.6.30 www.ffutop.com询问二级域名ffutop.com的权威服务器为ian.ns.cloudflare.com.和meera.ns.cloudflare.com.,并提供了对应的机器 IP。最后一步自然是三级域名
www.ffutop.com的 IP 啦。解析出来是104.28.24.190和104.28.25.190。
➜ ~ dig @198.41.0.4 www.ffutop.com
; <<>> DiG 9.10.6 <<>> @198.41.0.4 www.ffutop.com
; (1 server found)
;; QUESTION SECTION:
;www.ffutop.com. IN A
;; AUTHORITY SECTION:
com. 172800 IN NS a.gtld-servers.net.
# ... some records omitted ...
com. 172800 IN NS m.gtld-servers.net.
;; ADDITIONAL SECTION:
a.gtld-servers.net. 172800 IN A 192.5.6.30
# ... some records omitted ...
m.gtld-servers.net. 172800 IN A 192.55.83.30
;; Query time: 220 msec
;; SERVER: 198.41.0.4#53(198.41.0.4)
;; WHEN: Thu Feb 27 18:04:28 CST 2020
;; MSG SIZE rcvd: 839
这里我们额外地需要提一下,DNS 记录有不同的类型,像是
NS,A,AAAA,分别指代不同的记录类型,提供不同的记录内容。
A: 将域名指向 IPv4 地址
AAAA:将域名指向 IPv6 地址
NS:将域名授权给指定的权威域名服务器提供解析服务更多记录类型请自行搜索
代理 DNS 服务器工作原理
我们每次请求对一个域名进行解析,真的有这么多个查询请求吗?早期集中式的服务器服务能力有限,但现在的服务器依然无法逃脱服务上限,上述的解析必然地有一个对根域名服务器的请求,也就意味着,并没有改变集中式的不足?自然不是。撇开权威域名服务器,与我们上网关系更密切的,是代理 DNS 服务器。诸如 Google 的 8.8.8.8 ,114dns 的 114.114.114.114,还有更多的运营商的 DNS 服务,局域网内的路由器的 DNS 服务,都是这类代理域名服务器。域名解析的请求被它们接收,并代替我们执行上述递归查询的动作。而这类服务器对查询得到的结果,会按照记录所配置的 TTL (Time to Live)进行缓存,在缓存生效期间,不再重复向权威服务器进行查询。
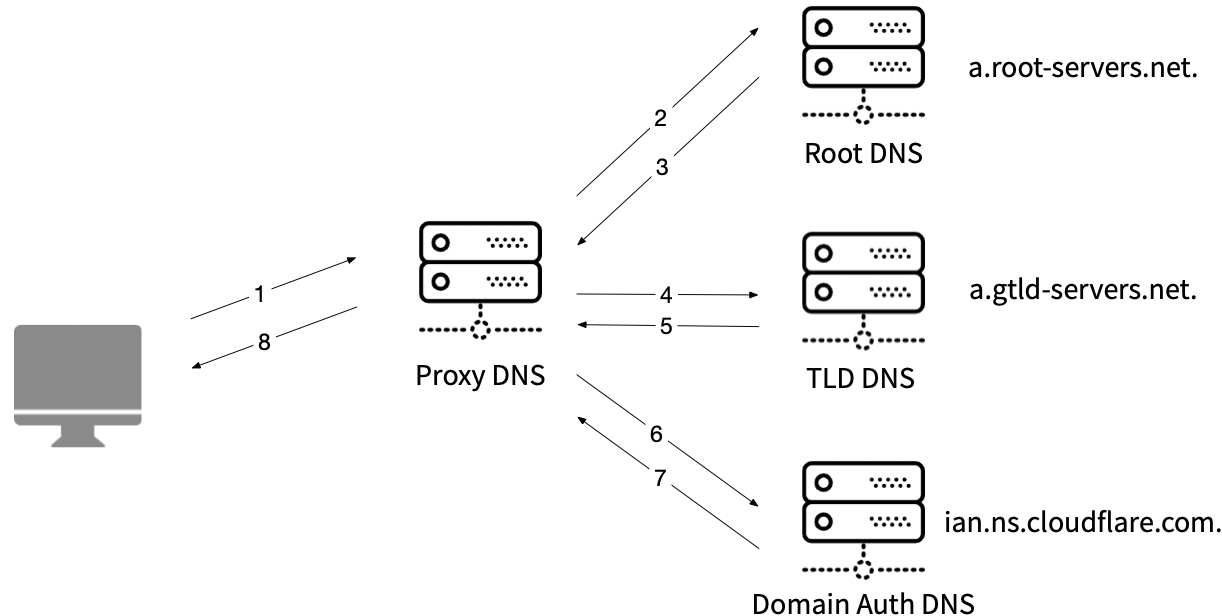
域名解析流程
在通常情况下,代理服务器也不是单级的,代理服务器也存在上游代理服务器,对于本级代理服务器没缓存的记录,优先向上级代理服务器询问。这种代理的方案极大地降低了对权威服务器的压力。但即使如此,权威服务器每天仍然承受着大量的请求。下图展示了根域名服务器A每日的请求量,对于 IPv4 UDP 请求,平均每日有 60 亿请求量。
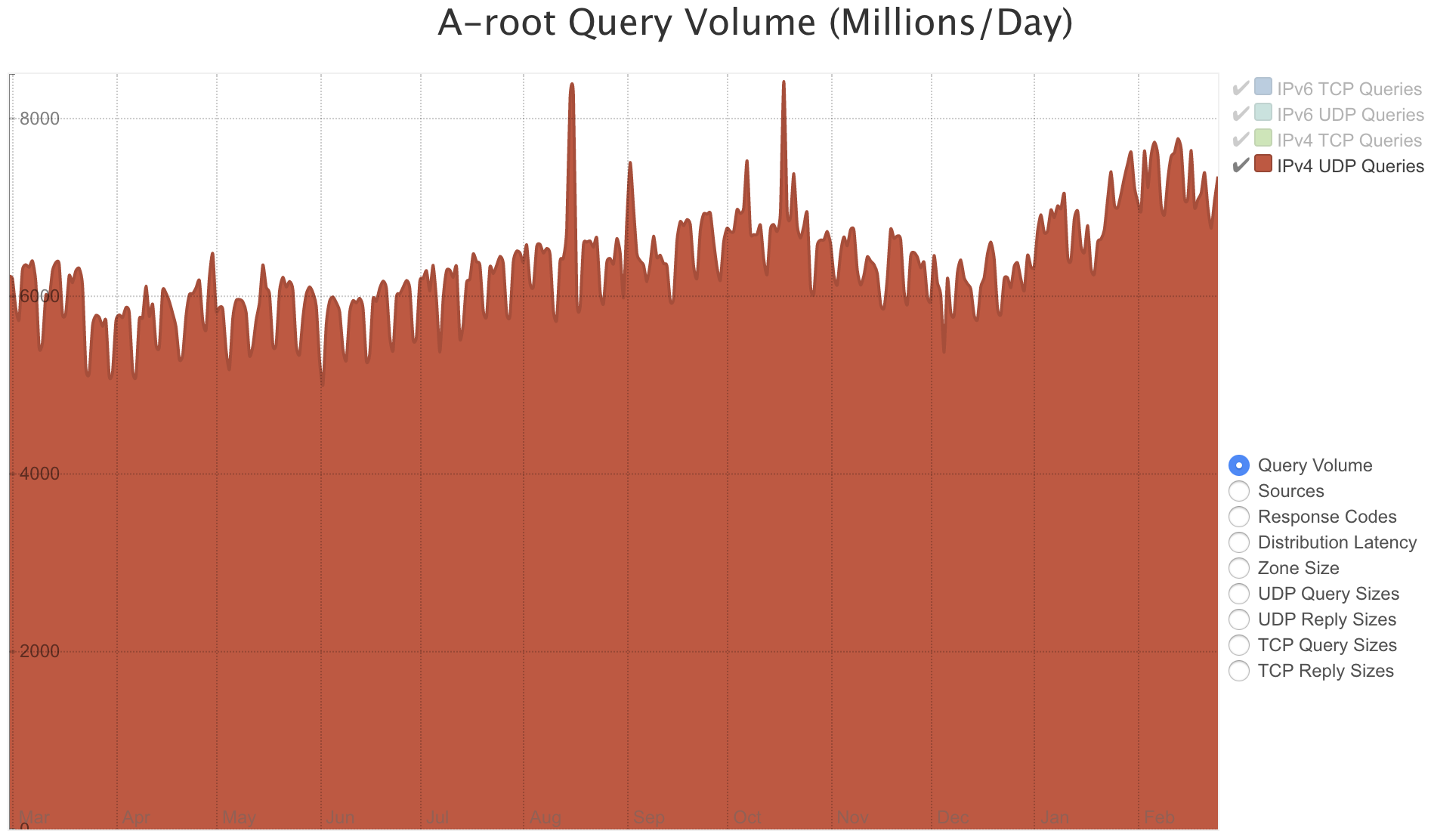
根域名服务器A每日请求量
另一方面,代理 DNS 服务器的存在,也极大地提供了域名解析的效率。不过,这些代理服务器的存在,也招致了 DNS 记录的更新费事费力,牵一发而动全身。将经历漫长的过渡期,才能逐级让下游代理服务器意识到记录已经过时。更可怕的是,部分代理 DNS 服务器不严格遵守 TTL ,而自行其是,更是加重了此类问题的不可预测性。
Java 的 DNS 解析缓存
无论是否有代理 DNS 服务器的存在,DNS 解析始终是一个耗时的操作。Java 对 DNS 解析,也提供了缓存实现。在启用 SecurityManager 时,所有有效域名解析将永久缓存;如果不启用,默认的策略将使域名解析结果缓存有限的时间。同时,任意失败的解析记录都将缓存一小段时间(以规避无意义的消耗)
整个解析的调用链路如下:
java.net.InetAddress.getByName(String host)
java.net.InetAddress.getAllByName(String host)
java.net.InetAddress.getAllByName(String host, InetAddress reqAddr)
java.net.InetAddress.getAllByName0(String host, InetAddress reqAddr, **boolean **check, **boolean **useCache)
通过 useCache 和缓存超时时间共同决定缓存的添加与过期
/** Source File: java.net.InetAddress */
private static InetAddress[] getAllByName0(String host, InetAddress reqAddr, boolean check, boolean useCache)
throws UnknownHostException {
// 从缓存中主动移除过期的记录 (如果这条记录的缓存时间预期会超时的话)
long now = System.nanoTime();
for (CachedAddresses caddrs : expirySet) {
if ((caddrs.expiryTime - now) < 0L) {
if (expirySet.remove(caddrs)) {
cache.remove(caddrs.host, caddrs);
}
} else {
break;
}
}
// look-up or remove from cache
Addresses addrs;
if (useCache) {
// 尝试在缓存中获取
addrs = cache.get(host);
} else {
// 如果 useCache = false,主动清理掉相关的缓存
addrs = cache.remove(host);
if (addrs != null) {
if (addrs instanceof CachedAddresses) {
expirySet.remove(addrs);
}
addrs = null;
}
}
if (addrs == null) {
// create a NameServiceAddresses instance which will look up
// the name service and install it within cache...
Addresses oldAddrs = cache.putIfAbsent(
host,
addrs = new NameServiceAddresses(host, reqAddr)
);
if (oldAddrs != null) { // lost putIfAbsent race
addrs = oldAddrs;
}
}
// ask Addresses to get an array of InetAddress(es) and clone it
return addrs.get().clone();
}
未命中缓存的将产生真实的 DNS 解析请求。使用 Cache 的情况下,缓存时间的配置来源于 java.security 文件中的 networkaddress.cache.ttl 和 networkaddress.cache.negative.ttl 。
如果 ttl 配置为负数,则表现为一次解析,结果缓存永不过期
如果 ttl 配置为非负,表现为解析结果的缓存时长。为 0 意味着不缓存。
如果 ttl 未配置,则默认对有效结果进行缓存,缓存时长 30 秒
/** Source File: java.net.InetAddress */
public InetAddress[] get() throws UnknownHostException {
Addresses addresses;
// only one thread is doing lookup to name service
// for particular host at any time.
synchronized (this) {
// re-check that we are still us + re-install us if slot empty
addresses = cache.putIfAbsent(host, this);
if (addresses == null) {
// this can happen when we were replaced by CachedAddresses in
// some other thread, then CachedAddresses expired and were
// removed from cache while we were waiting for lock...
addresses = this;
}
// still us ?
if (addresses == this) {
// lookup name services
InetAddress[] inetAddresses;
UnknownHostException ex;
int cachePolicy;
try {
inetAddresses = getAddressesFromNameService(host, reqAddr);
ex = null;
cachePolicy = InetAddressCachePolicy.get();
} catch (UnknownHostException uhe) {
inetAddresses = null;
ex = uhe;
cachePolicy = InetAddressCachePolicy.getNegative();
}
// remove or replace us with cached addresses according to cachePolicy
if (cachePolicy == InetAddressCachePolicy.NEVER) {
cache.remove(host, this);
} else {
CachedAddresses cachedAddresses = new CachedAddresses(
host,
inetAddresses,
cachePolicy == InetAddressCachePolicy.FOREVER
? 0L
// cachePolicy is in [s] - we need [ns]
: System.nanoTime() + 1000_000_000L * cachePolicy
);
if (cache.replace(host, this, cachedAddresses) &&
cachePolicy !=
.FOREVER) {
// schedule expiry
expirySet.add(cachedAddresses);
}
}
if (inetAddresses == null) {
throw ex == null ? new UnknownHostException(host) : ex;
}
return inetAddresses;
}
// else addresses != this
}
// delegate to different addresses when we are already replaced
// but outside of synchronized block to avoid any chance of dead-locking
return addresses.get();
}
数据库切换方案
我们计划将服务 A 的主从数据库 MDB/RDB 从老实例集群迁移到新实例集群。MDB/RBD 的实例域名不变,但背后绑定的两个 IP 将发生变化。为了规避 Java DNS 缓存的影响,我们选择了最简单的停机重启。至于 DNS 记录更新,使用云服务商的内网 DNS 服务,在方案中,它被认为是与自建内网 DNS 服务器同等的服务。虽然 TTL = 3600,但新记录将完全覆盖老记录(毕竟中间没有代理服务器的存在,可以简单地看做是集中式的服务,新老记录做替换。T_T 这恰恰是方案中一个致命的问题)
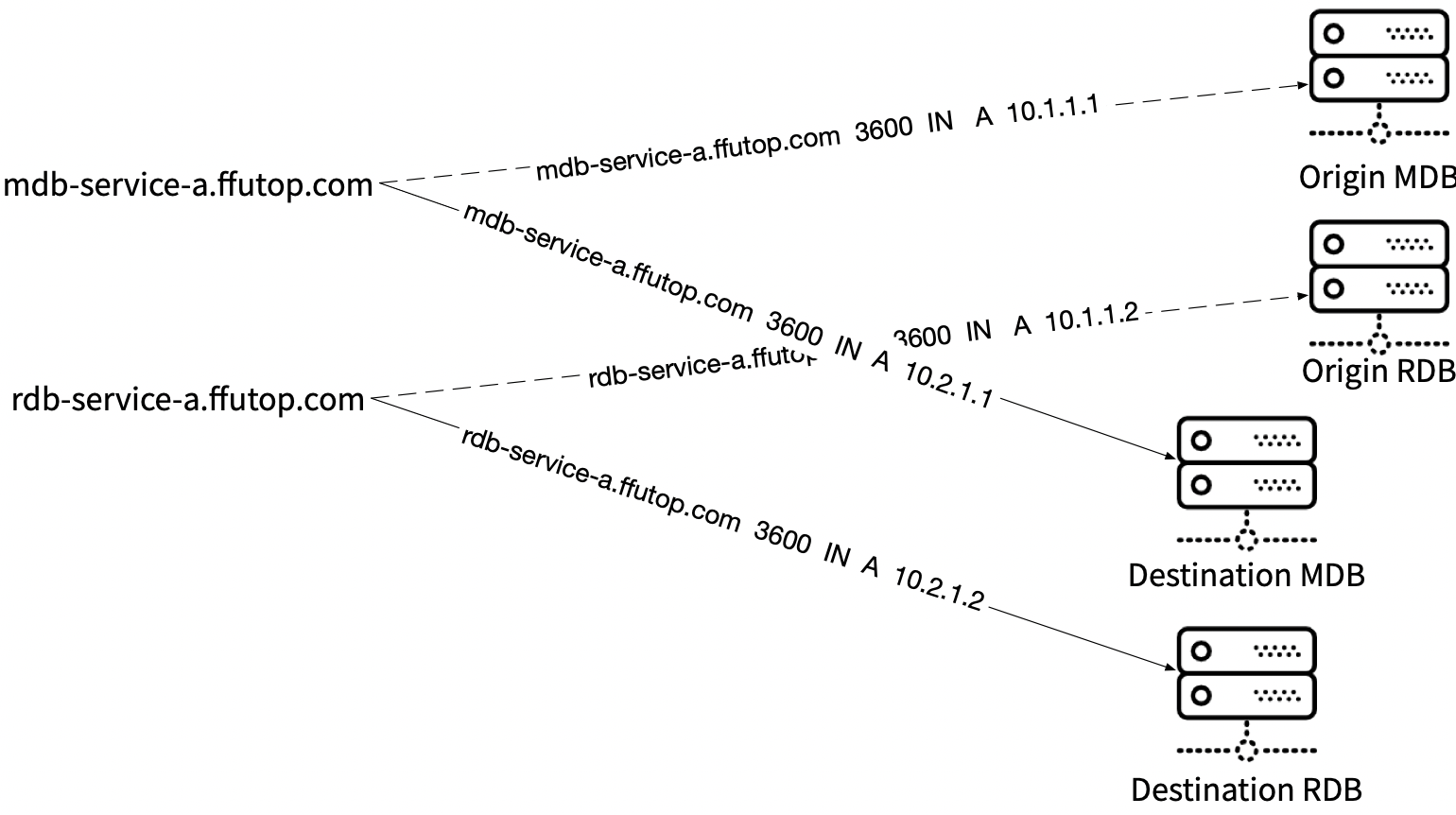
数据库切换方案
事故复盘
很遗憾,最后数据库切换失败。本来是充分利用 DNS 灵活的特性让切换更便捷,结果应用同时连接上了新老两套数据库,为修复数据反而付出了更大的代价。
从表现上来看,这个内网 DNS 服务更像是代理 DNS 服务器的存在,有限的区别在于,额外承担了内网域名解析的功能,通过控制台新增/修改的域名记录将主动下发给这个服务器,但它不会覆盖原有的记录(原记录将基于 TTL 自动过期,但不会被主动删除)。
 DNS 记录状态
DNS 记录状态
记录将保持上图的状态,同时存在新老记录,并表现为轮询的方式对 DNS 解析请求进行响应。
从 Java 程序的角度看,使用了默认的配置,成功的 DNS 解析记录将缓存 30 秒。
再外一层,Java 程序作为 Kubernetes 集群的 Pod 存在,集群提供的代理 DNS 服务器 CoreDNS 配置的缓存时间也是 30 秒。
再追溯,CoreDNS 以内网 DNS 服务为上游,而这个服务在此 1 小时内(因为 TTL 被配置为 3600),将轮询着响应新老两种域名解析结果,直到老记录随着 TTL 为 0 过期。
结果就表现成了,重启的 Java 应用,成功规避了应用本身的缓存,但却被云服务商的 DNS 服务坑了一把。有新有老的 DNS 记录,让数据库连接池中的连接偶尔连接上了新的数据库,偶尔又连接了老的数据库。T_T
解决方案
解决方案也相当丰富:
强制写 Java DNS 解析记录(工具),不依赖外部的 DNS 服务
使用受控的 Kubernetes CoreDNS 服务,强制写两条 DNS 记录,暂时停止这两条记录对上游的依赖。直到老记录完全失效
改写主机
/etc/hosts记录仍然依赖云服务商的内网 DNS 服务,但提前缩短老记录的 TTL(比如 5 秒,60 秒),让切换的时间周期缩短到可接受的程度。
more …
参考文档
[1]. DOMAIN NAMES - CONCEPTS AND FACILITIES https://tools.ietf.org/html/rfc1034
[2]. DOMAIN NAMES - IMPLEMENTATION AND SPECIFICATION** **https://tools.ietf.org/html/rfc1035
[3]. IANA, Domain Name Services https://www.iana.org/domains
[4]. Versign, Root name servers A. https://a.root-servers.org/index.html