基于这个问题,本篇将整理并总结个人的结论。
什么是幂等
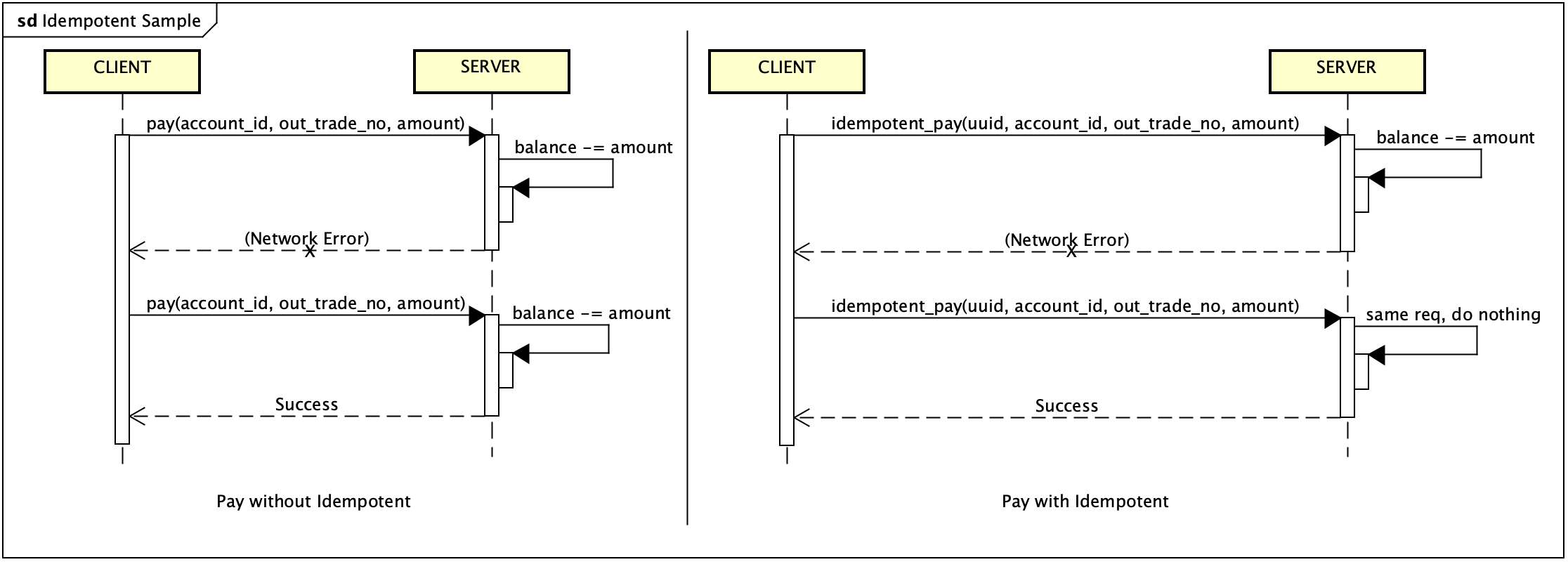
幂等是指对于同一操作发起的一次或多次请求的结果是一致的,不会因为多次请求而产生多余的副作用。常见的例子:对同一订单,只需支付一次全款。如果首次成功发起支付但因为网络原因没有收到支付成功的响应。用户发起了对付款的重试操作,幂等性的接口需要保证,既不能二次扣款,又需要提供与第一次相同的响应。
何谓“同一操作”?两次支付请求,可能是分别属于两张订单的;也可能是同一张订单,但第一次支付由于余额不足支付失败,在存入现金后发起了第二次支付…相比于服务调用方(Client, 下同),服务提供方(Server,下同)无法直接判断请求是否为同一操作,即使请求参数完全相同,背后的意义也可能出现了差别。更加贴近用户的服务调用方,更适合于定义同一操作。由 Client 提供唯一标识符,Server 可以直接认定操作的“同一”性。
一般来说,幂等是服务提供方给的担保,保证“同一操作”的重试结果一致,没有多余副作用。但是,这个担保背后,也意味着 Server 原本纯粹的接口,需要承担额外的工作,为可能的重试建立防御措施。特别的,这个担保并没有想象中的简单。举个片面的例子:为保证幂等,定义了同一操作的唯一标识符需要如何维护,维护多久?如果重试可能发生在第二天、第二年,这个维护的代价未免太大了吧。
哪些场景需要幂等
在讨论幂等场景前,我们需要意识到有一些场景天然地幂等。读操作天然地幂等,多次重复的请求不会对背后的数据带来副作用。至于你可能会疑惑多次请求,响应数据的一致性问题?我想这就需要先探讨一下是否有场景必须在一次读请求成功后,发起二次读请求,并将这两次读操作认定是“同一操作”了。至少在我看来这是不存在。因此,读操作天然地幂等,也就无需讨论它的场景了。
拿 CRUD 来讲,R (Read, 读取) 和 D (Delete, 删除) 也几乎是天然地幂等,而 C (Create, 创建) 和 U (Update, 更新) 才应该拿来被讨论幂等。
那么,对于非天然幂等的操作,是否都需要提供幂等的保证呢?当然不是了。初始问题 已经表明了广受欢迎的 Redis 并不提供幂等保证。个人认为,判定是否需要 Server 提供幂等有两个重要的条件:
- Server 提供的服务的性质,是否能自行容错(类似统计浏览量的服务,虽然非天然幂等,但却能极大地容错)
- Client 通过判定数据状态来决定重试的代价 vs Server 提供幂等保证的代价
对于提供高效 Key/Value 操作的 Redis 而言,面对请求无响应等情况,通过检查 Key/Value 来决定是否重试的非常经济的办法。而让 Server 提供幂等保证,就意味着 Key/Value 服务将不得不建立一套附属机制。
而分布式场景大规模集群下,不可靠带来的问题如果由 Client 来负责,意味着连 Server 的死活都是 Client 不得不思考的问题。
如何实现幂等
实现幂等又有两条不同的路径。
- 主动实现幂等:Server 建立一种机制来确认每一个 Client 发来的请求是否曾经被处理过,如果是的,那么不重复直接而直接给出响应。也就是 Server 提供的担保,Client 可以多次重试,无副作用
- 被动实现幂等:通过特殊的设计让重试操作在 Server 侧的数据操作失败。例如 CAS (Compare and Swap)、RDBMS Unique Key
主动实现幂等
主动实现幂等的方案中,比较常见的一种就是对请求进行唯一标定。客户端对每次请求标定 uuid,重试请求使用原请求相同的 uuid;服务端基于 uuid 判定请求是首次收到或重复收到(这里需要注意,Client 的重试对 Server 也可能意味着是首次收到。比如请求时网络故障的情况。)这种方案意味着 Server 需要对请求标识做缓存,并定义最久可能发生重试的时间。如果请求量庞大,这个方案意味着巨大存储的开销,并需要额外的机制来确保缓存机制的可靠性。
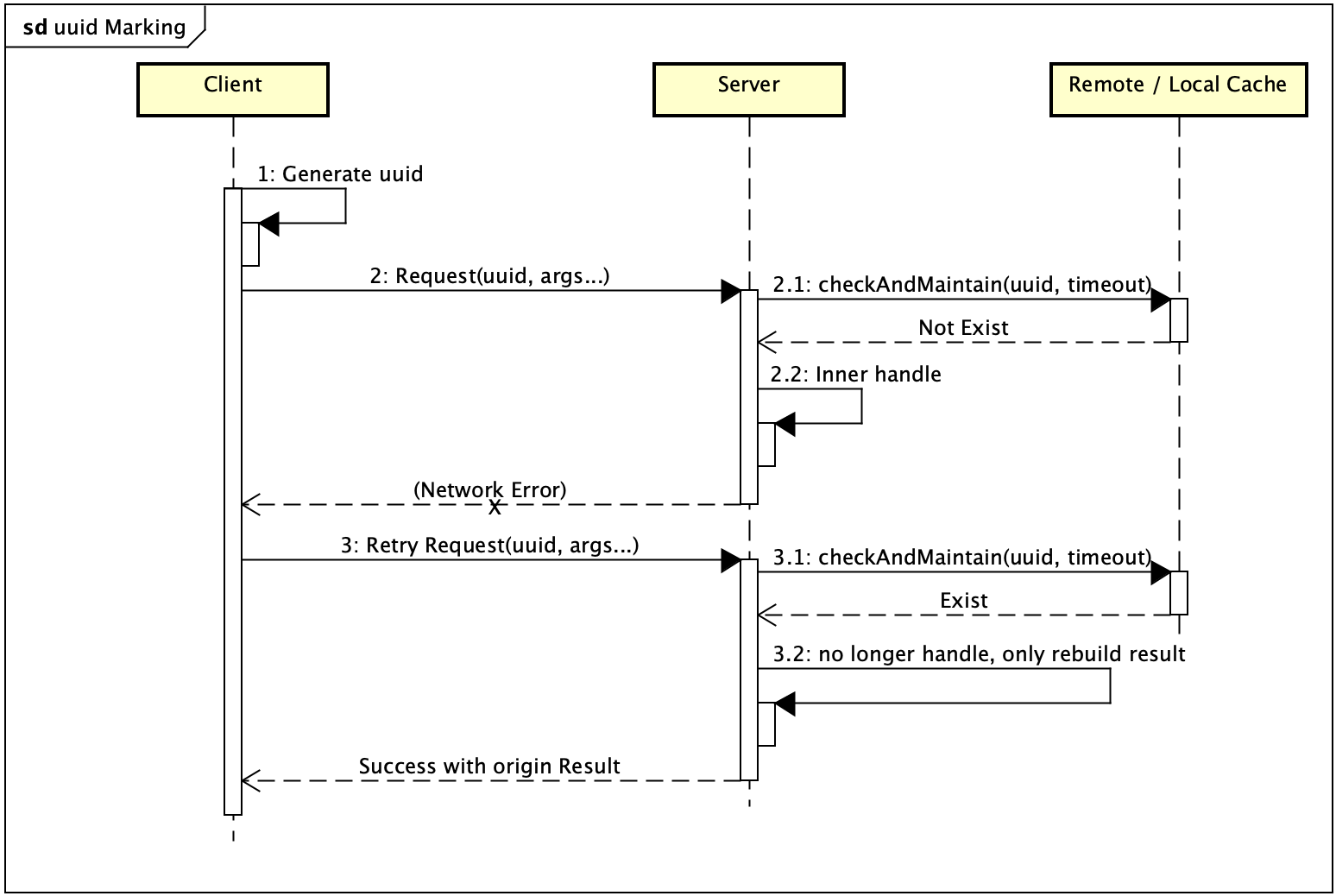
用唯一标识符标定请求的方案,也有各种各样的变种。个人最有意思的方案是:
基于会话的 C-S 通信中,用 SessionID + ReqID 来替代请求的 uuid。SessionID 与会话绑定,用 uuid 标识;ReqID 基于 SessionID,每个不同的请求逐一递增,重试请求使用相同的 ReqID 。Server 只需要维护对每个 SessionID,目前处理到的最新的 ReqID 是多少就可以了。如果收到的 ReqID 小于 Server 维护的相应 SessionID 的最新 ReqID,那就主动丢弃(这个请求应该认为是网络延迟导致的包提交到应用比较晚,而 Client Session 早就进行到了构建新的请求)。
这个方案可以极大地减少需要幂等需要维护的缓存开销。也算是对连接进行了充分的复用。
从合理性的角度来说,主动式的幂等,需要 Client 来对请求进行唯一标定,毕竟只有发起方才能定义重试 or 新请求。不过,也经常发生 Client 根本不管,而把这些烂活全部交给 Server 的情况。此时对重试的判定就变得困难,但通过约定或业务语意,也能在一定程度上实施幂等机制。
被动实现幂等
被动式的幂等多种多样,一般都是特殊操作让重试恰好失败。
乐观锁机制也可以实现幂等。用 SQL 示例来描述就是,UPDATE db.tableA SET state = 2 WHERE id = 1 AND state = 1。只有 state=1 时,对数据的修改操作才会生效,一旦数据修改成功,重试不会导致重复更改。当然,这种方案需要比较苛刻的条件,如果在重试前,另一个请求进行的是 UPDATE db.tableA SET state=1 WHERE id=1;那么幂等就已经被破坏了。也就是强依赖于状态机的状态流转。
类似的,像数据库唯一键约束等,也可以保证面对重试,数据不会因此产生问题。
总结
回到最初的问题,事实上两个对象不具有对比性。同样是 KV-Server,可比较的对象是 Redis VS etcd (这类基于 Raft Algorithm 实现的分布式 KV-Server)。从 KV-Server 的角度来看,它们提供足够简单高效的 KV 服务,无关幂等,事实上也没有实现幂等。而 etcd 这类分布式 KV-Server 之所以被描述为需要幂等,是整个集群内部,把接受集群外请求的节点作为 Client,向集群内 Leader 发起请求,因为分布式网络不可靠程度更甚而需要 Server 端主动地提供幂等机制。