译者序
本文来自 Timescale - Implementing constraint exclusion for faster query performance 。主要介绍 TimescaleDB 官方如何利用 PostgreSQL 节点及自定义扫描节点,实现三种不同场景下的查询性能优化。
译者水平有限,不免存在遗漏或错误之处。如有疑问,敬请查阅原文。
以下是译文。
在 PostgreSQL 中执行查询时实际会发生什么
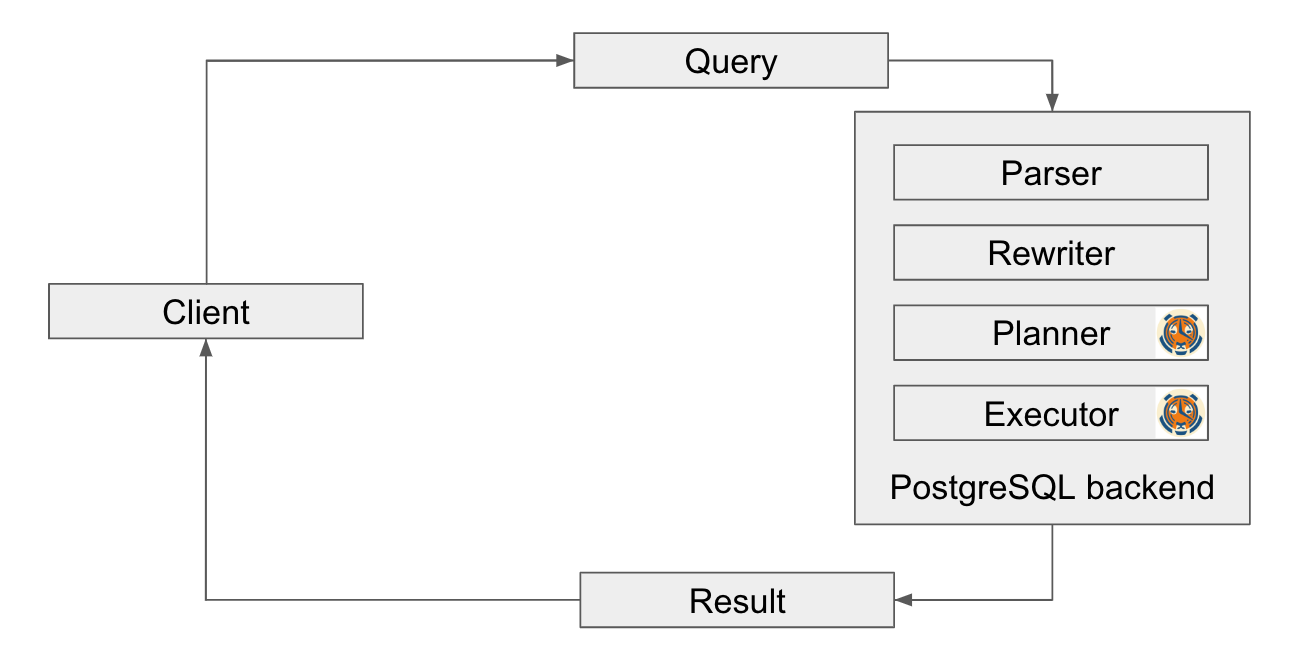
应用程序与 PostgreSQL 服务器建立连接后,程序会向服务器发送查询并等待结果。解析器根据静态语法定义验证查询并生成解析树,然后执行语义分析并检查引用对象的目录从而生成查询树。接下来,重写器获取查询树并检索要应用的规则。例如,如果查询是面向视图的 (SELECT … FROM VIEW),则重写器将重写查询为面向表的 (SELECT … FROM TABLE)。
查询规划器生成不同的路径,这些路径都可以产生所需的查询结果,并各自维护一个查询成本。最经济的路径就会成为执行器使用的计划。执行器在扫描关系的同时利用存储系统进行排序和连接,评估资格,最终创建结果。
每个 PostgreSQL 函数都有一个易变性分类,可以将其定义为对优化器关于函数行为的承诺。以下是三类:
- 不可变(Immutable):无法修改数据库;保证在给定相同参数的情况下永远返回相同的结果,可以在计划阶段安全地评估。例如 length()
- 稳定(Stable):无法修改数据库;保证在同一查询中给定相同参数时返回相同结果,可以在执行期间安全地进行评估。例如 now()
- 易失性(Volatile):可以修改数据库;能够在使用相同参数的连续调用中返回不同的结果。例如 random()
由于运算符被视为函数的一种实例,因此表达式从表达式中使用的函数继承其易变性分类。这些表达式基于它们的易变性分类,在不同的阶段实现约束排除。易变性还决定了表达式是否可以在索引扫描中使用——只有不可变或稳定的表达式可以用作索引扫描中的条件。
PostgreSQL 仅在计划阶段对表执行约束排除。运行时约束排除仅限于 PG11+ 中使用原生分区的表。在 TimescaleDB 1.4 中,我们对规划器进行了多项改进,使用户能够从约束排除中受益,即使对于无法利用计划阶段 PostgreSQL 内置约束排除的查询也是如此。
如何在执行时实现约束排除
PostgreSQL 使用“节点”来描述如何执行计划。EXPLAIN 输出中可能会出现各种不同的节点,但我们将只关注 Append 节点,这些节点本质上将多个来源的结果组合成一个结果。
PostgreSQL 有两个常用的标准 Append:
- Append:追加子节点的结果以返回联合结果
- MergeAppend:按排序键合并子节点的输出;所有子节点必须按相同的排序键排序
为了在执行时使用约束排除,我们添加了一些 TimescaleDB 自定义节点:
- ConstraintAwareAppend:在执行器启动时实现约束排除;通常位于 Append 或 MergeAppend 节点之上
- ChunkAppend:实现执行器启动和运行时排除,并使 Append 有序;在 TimescaleDB 中,它用于取代 Append 节点,有时也取代 MergeAppend
第一阶段:规划器阶段约束排除
我们之前讨论过 PostgreSQL 的约束排除如何只能在计划期间应用,但无论如何,它仍然可以带来显著的性能改进。约束排除的第一阶段是规划器排除,它防止不需要的块进入查询计划。该场景对分区列有约束的查询非常有用,不过它只使用于不可变类型的表达式。
例如,我们要执行以下查询:
SELECT * FROM hypertable WHERE time < '2000-01-03'
在没有优化之前,我们可以看到执行计划:
dev=# EXPLAIN (ANALYZE,COSTS OFF,BUFFERS,TIMING OFF,SUMMARY OFF)
SELECT * FROM metrics WHERE time < '2000-01-03';
QUERY PLAN
---------------------------------------------------------------------------------------------------------
Append (actual rows=2880 loops=1)
Buffers: shared hit=39
-> Seq Scan on metrics (actual rows=0 loops=1)
Filter: ("time" < '2000-01-03 00:00:00+01'::timestamp with time zone)
-> Index Scan using _hyper_1_1_chunk_metrics_time_idx on _hyper_1_1_chunk (actual rows=2880 loops=1)
Index Cond: ("time" < '2000-01-03 00:00:00+01'::timestamp with time zone)
Buffers: shared hit=31
-> Index Scan using _hyper_1_2_chunk_metrics_time_idx on _hyper_1_2_chunk (actual rows=0 loops=1)
Index Cond: ("time" < '2000-01-03 00:00:00+01'::timestamp with time zone)
Buffers: shared hit=2
-> Index Scan using _hyper_1_3_chunk_metrics_time_idx on _hyper_1_3_chunk (actual rows=0 loops=1)
Index Cond: ("time" < '2000-01-03 00:00:00+01'::timestamp with time zone)
Buffers: shared hit=2
-> Index Scan using _hyper_1_4_chunk_metrics_time_idx on _hyper_1_4_chunk (actual rows=0 loops=1)
Index Cond: ("time" < '2000-01-03 00:00:00+01'::timestamp with time zone)
Buffers: shared hit=2
-> Index Scan using _hyper_1_5_chunk_metrics_time_idx on _hyper_1_5_chunk (actual rows=0 loops=1)
Index Cond: ("time" < '2000-01-03 00:00:00+01'::timestamp with time zone)
Buffers: shared hit=2
而优化后,执行计划:
dev=# EXPLAIN (ANALYZE,COSTS OFF,BUFFERS,TIMING OFF,SUMMARY OFF)
SELECT * FROM metrics WHERE time < '2000-01-03';
QUERY PLAN
---------------------------------------------------------------------------------------------------------
Append (actual rows=2880 loops=1)
Buffers: shared hit=31
-> Index Scan using _hyper_1_1_chunk_metrics_time_idx on _hyper_1_1_chunk (actual rows=2880 loops=1)
Index Cond: ("time" < '2000-01-03 00:00:00+01'::timestamp with time zone)
Buffers: shared hit=31
正如您所看到的,通过在计划阶段实施约束排除,我们能够防止不需要的块进入我们的查询计划。
第二阶段:执行器启动阶段约束排除
第二阶段发生在查询执行器初始化期间,并在执行之前删除不需要的块。该场景对于对分区列有约束的查询非常有用,并且适用于任何稳定类型的表达式。
例如,假设我们要执行以下查询:
SELECT * FROM hypertable WHERE time < now()
经过优化,计划如下:
dev=# EXPLAIN (ANALYZE,COSTS OFF,BUFFERS,TIMING OFF,SUMMARY OFF)
SELECT * FROM metrics WHERE time < now() - interval '19years 5month 28days';
QUERY PLAN
---------------------------------------------------------------------------------------------------------
Custom Scan (ChunkAppend) on metrics (actual rows=2389 loops=1)
Chunks excluded during startup: 4
Buffers: shared hit=26
-> Index Scan using _hyper_1_1_chunk_metrics_time_idx on _hyper_1_1_chunk (actual rows=2389 loops=1)
Index Cond: ("time" < (now() - '19 years 5 mons 28 days'::interval))
Buffers: shared hit=26
虽然此计划与之前的查询类似,但 now() 函数使表达式无法进行规划器阶段约束排除。对于执行器启动阶段约束排除,TimescaleDB 使用我们的自定义扫描节点(ChunkAppend)来删除不需要的超表块。
第三阶段:执行器运行阶段排除
最后一个场景发生在执行期间。它可以防止在执行过程中命中不需要的块,并应用于对运行时值的任何引用。此函数对于嵌套循环连接、横向连接和子查询特别有用。
例如,假设我们要执行以下查询:
SELECT * FROM hypertable WHERE time = (SELECT max(time) FROM hypertable)
dev=# EXPLAIN (ANALYZE,COSTS OFF,BUFFERS,TIMING OFF,SUMMARY OFF)
SELECT * FROM metrics WHERE time = (SELECT max(time) FROM metrics);
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------
Custom Scan (ChunkAppend) on metrics (actual rows=1 loops=1)
Chunks excluded during runtime: 4
Buffers: shared hit=18
InitPlan 2 (returns $1)
-> Result (actual rows=1 loops=1)
Buffers: shared hit=3
InitPlan 1 (returns $0)
-> Limit (actual rows=1 loops=1)
Buffers: shared hit=3
-> Custom Scan (ChunkAppend) on metrics metrics_1 (actual rows=1 loops=1)
Order: metrics_1."time" DESC
Buffers: shared hit=3
-> Index Only Scan Backward using _hyper_1_5_chunk_metrics_time_idx on _hyper_1_5_chunk _hyper_1_5_chunk_1 (actual rows=1 loops=1)
Index Cond: ("time" IS NOT NULL)
Heap Fetches: 1
Buffers: shared hit=3
-> Index Only Scan Backward using _hyper_1_4_chunk_metrics_time_idx on _hyper_1_4_chunk _hyper_1_4_chunk_1 (never executed)
Index Cond: ("time" IS NOT NULL)
Heap Fetches: 0
-> Index Only Scan Backward using _hyper_1_3_chunk_metrics_time_idx on _hyper_1_3_chunk _hyper_1_3_chunk_1 (never executed)
Index Cond: ("time" IS NOT NULL)
Heap Fetches: 0
-> Index Only Scan Backward using _hyper_1_2_chunk_metrics_time_idx on _hyper_1_2_chunk _hyper_1_2_chunk_1 (never executed)
Index Cond: ("time" IS NOT NULL)
Heap Fetches: 0
-> Index Only Scan Backward using _hyper_1_1_chunk_metrics_time_idx on _hyper_1_1_chunk _hyper_1_1_chunk_1 (never executed)
Index Cond: ("time" IS NOT NULL)
Heap Fetches: 0
-> Index Scan using _hyper_1_1_chunk_metrics_time_idx on _hyper_1_1_chunk (never executed)
Index Cond: ("time" = $1)
-> Index Scan using _hyper_1_2_chunk_metrics_time_idx on _hyper_1_2_chunk (never executed)
Index Cond: ("time" = $1)
-> Index Scan using _hyper_1_3_chunk_metrics_time_idx on _hyper_1_3_chunk (never executed)
Index Cond: ("time" = $1)
-> Index Scan using _hyper_1_4_chunk_metrics_time_idx on _hyper_1_4_chunk (never executed)
Index Cond: ("time" = $1)
-> Index Scan using _hyper_1_5_chunk_metrics_time_idx on _hyper_1_5_chunk (actual rows=1 loops=1)
Index Cond: ("time" = $1)
Buffers: shared hit=3
您会注意到,我们确定不需要在运行时访问的块在计划中被标记为“从不执行(never executed)”。